Before you begin
The following applies to minimal websites that focus primarily on text. It does not apply to websites that have a lot of non-textual content. It also does not apply to websites that focus more on generating revenue or pleasing investors than being inclusive.
This is a “living document” that I add to as I receive feedback. See the updated date and changelog after the post title.
If you find the article too long, just read the introduction and conclusion. The table of contents should help you skim.
Toggle table of contents
Introduction
I realize not everybody’s going to ditch the Web and switch to Gemini or Gopher today (that’ll take, like, at least a month /s). Until that happens, here’s a non-exhaustive, highly-opinionated list of best practices for websites that focus primarily on text. I don’t expect anybody to fully agree with the list; nonetheless, the article should have at least some useful information for any web content author or front-end web developer.
Inclusive design
My primary focus is inclusive design. Specifically, I focus on supporting underrepresented ways to read a page. Not all users load a page in a common web-browser and navigate effortlessly with their eyes and hands. Authors often neglect people who read through accessibility tools, tiny viewports, machine translators, “reading mode” implementations, the Tor network, printouts, hostile networks, and uncommon browsers, to name a few. I list more niches in the conclusion. Compatibility with so many niches sounds far more daunting than it really is: if you only selectively override browser defaults and use plain-old, semantic HTML (POSH), you’ve done half of the work already.
One of the core ideas behind the flavor of inclusive design I present is inclusivity by default. Web pages shouldn’t use accessible overlays, reduced-data modes, or other personalizations if these features can be available all the time. Personalization isn’t always possible: Tor users, students using school computers, and people with restrictive corporate policies can’t “make websites work for them”; that’s a webmaster’s responsibility.
At the same time, many users do apply personalizations; sites should respect those personalizations whenever possible. Balancing these two needs is difficult. Some features conflict; you can’t display a light and dark color scheme simultaneously. Personalization is a fallback strategy to resolve conflicting needs. Disproportionately underrepresented needs deserve disproportionately greater attention, so they come before personal preferences instead of being relegated to a separate lane.
Restricted enhancement
Another focus is minimalism. Progressive enhancement is a simple, safe idea that tries to incorporate some responsibility into the design process without rocking the boat too much. I don’t find it radical enough. I call my alternative approach “restricted enhancement”.
Restricted enhancement limits all enhancements to those that solve specific accessibility, security, performance, or significant usability problems faced by people besides the author. These enhancements must be made progressively when possible, with a preference for using older or more widespread features, taking into account unorthodox user agents. Purely-cosmetic changes should be kept to a minimum.
I’d like to re-iterate yet another time that this only applies to websites that primarily focus on text. If graphics, interactivity, etc. are an important part of your website, less of the article applies. My hope is for readers to consider a subset of this page the next time they build a website, and address the trade-offs they make when they deviate. I don’t expect—or want—anybody to follow all of my advice, because doing so would make the Web quite a boring place!
Our goal: make a textual website maximally inclusive, using restricted enhancement.
Prior art
You can regard this article as an elaboration on existing work by the Web Accessibility Initiative (WAI).
I’ll cite the WAI’s Techniques for WCAG 2.2 a number of times. Each “Success Criterion” (requirement) of the WCAG has possible techniques. Unlike the Web Content Accessibility Guidelines (WCAG), the Techniques document does not list requirements; rather, it serves to non-exhaustively educate authors about how to use specific technologies to comply with the WCAG. I don’t find much utility in the technology-agnostic goals enumerated by the WCAG without the accompanying technology-specific techniques to meet those goals.
I’ll also cite Making Content Usable for People with Cognitive and Learning Disabilities, by the WAI. The document lists eight objectives. Each objective has associated personas, and can be met by several design patterns.
Why this article exists
Performance and accessibility guidelines are scattered across multiple WAI documents and blog posts. Moreover, guidelines tend to be overly general and avoid giving specific advice. Guidelines from different places tend to contradict each other, especially when they have different goals (e.g., security and accessibility). They also tend to be focused on large corporate sites rather than the simple text-oriented content the Web was made for.
I wanted to create a single reference with non-contradictory guidelines, containing advice more specific and opinionated than existing material. I also wanted to approach the very different aspects of site design from the same perspective and in the same place, allowing readers to draw connections between them.
Security and privacy
One of the defining differences between textual websites and advanced Web 2.0 sites/apps is safety. Most browser vulnerabilities are related to modern Web features like JavaScript and WebGL. The simplicity of basic textual websites should guarantee some extra safety; however, webmasters need to take additional measures to ensure limited use of “modern” risky features.
TLS
Hostile networks are the norm, and your site is an attack vector. All of the simplicity in the world won’t protect a page from unsafe content injection by an intermediary. Proper use of TLS protects against page alteration in transit and ensures a limited degree of privacy. Test your TLS setup with testssl.sh and Webbkoll.
If your OpenSSL (or equivalent) version is outdated or you don’t want to download and run a shell script, SSL Labs’ SSL Server Test should be equivalent to testssl.sh. Mozilla’s HTTP Observatory offers a subset of Webbkoll’s features and is a bit out of date (and requires JavaScript), but it also gives a beginner-friendly score. Most sites should strive for at least a 50, but a score of 100 or even 120 shouldn’t be too hard to reach.
A false sense of security is far worse than transparent insecurity. Don’t offer broken TLS ciphers, including TLS 1.0 and 1.1. Vintage computers can run TLS 1.2 implementations such as BearSSL surprisingly efficiently, leverage a TLS terminator, or they can use a plain unencrypted connection. Ancienne 2.0 brings TLS 1.3 to 90s-era machines. A broken cipher suite is security theater.
Scripts and the Content Security Policy
Consider taking hardening measures to maximize the security benefits made possible by the simplicity of textual websites, starting with script removal.
JavaScript and WebAssembly are responsible for the bulk of modern web exploits. If that isn’t reason enough, most non-mainstream search indexes have little to no support for JavaScript. Ideally, a text-oriented site can enforce a scripting ban at the Content Security Policy (CSP) level.
default-src 'none';
img-src 'self';
media-src 'self';
style-src 'sha256-HASH';
frame-ancestors 'none';
base-uri 'none';
form-action FORM_DESTS;
manifest-src 'self';
upgrade-insecure-requests;
sandbox allow-same-origin allow-forms
default-src: 'none' implies script-src: 'none', causing a compliant browser to forbid the loading of scripts. Furthermore, the sandbox CSP directive forbids a wide variety of risky actions. While script-src restricts script loading, sandbox can also restrict script execution with stronger defenses against script injection (e.g. by a browser add-on).note 1 I added the allow-same-origin parameter so that signed scripts (e.g. from add-ons) will still be able to function.note 2
If you’re able to control your HTTP headers, then use headers instead of a <meta http=equiv> tag. In addition to not supporting certain directives, a CSP in a <meta> tag might let some items slip through.
At the time of inserting the
metaelement to the document, it is possible that some resources have already been fetched. For example, images might be stored in the list of available images prior to dynamically inserting ametaelement with anhttp-equivattribute in the Content security policy state. Resources that have already been fetched are not guaranteed to be blocked by a Content Security Policy that’s enforced late.
If you must enable scripts
Please use progressive enhancement (PE)note 3 throughout your site; every feature possible should be optional, and scripting is no exception.
I’m sure you’re a great person, but your readers might not know that; don’t expect them to trust your website. Your scripts should look as safe as possible to an untrusting eye. Avoid requesting permissions or using sensitive APIs.
Finally, consider using your CSP to restrict script loading. If you must use inline scripts, selectively allow them with a hash or nonce. Some recent CSP directives restrict and enforce proper use of trusted types.
Third-party content
Third-party content will complicate the CSP, allow more actors to track users, possibly slow page loading, and create more points of failure. Some privacy-conscious users actually block third-party content: while doing so is fingerprintable, it can reduce the amount of data collected about an already-identified user. Avoid third-party content, if at all possible.
Some web developers deliver resources using a third-party content delivery network (CDN), such as jsDelivr or Unpkg. Traditional wisdom held that doing so would allow different websites to re-use cached resources; however, mainstream browsers partition their caches to prevent this behavior.
If you must use third-party content, use subresource integrity (check the SRI specification). This prevents alteration without your consent. If you wish to be extra careful, you could use SRI for first-party resources too.
Be sure to check the privacy policies for the third party services and subscribe to updates, as their practices could impact the privacy of all your users.
For embedded third-party content (e.g. images), give extra consideration to the “Beyond alt-text” section. Your page should be as useful as possible if the embedded content becomes inaccessible.
Optimal loading
Nearly every Internet user has to deal with unreliable connections every now and then, even the most privileged. Developing regions lack modern Internet infrastructure; high-ranking executives travel frequently. Everybody hits the worst end of the bell-curve.
Reducing load time is especially useful to poorly-connected users. For much of the world, connectivity comes in short bursts during which loading time is precious. Chances of a connection failure or packet loss increase with time.
Optimal loading is a complex topic. Broadly, it covers three overlapping categories: reducing payload size, delivering content early, and reducing the number of requests and round trips.
Blocking resources
HTML is a blocking resource: images and stylesheets will not load until the user agent loads and parses the HTML that calls them. To start loading above-the-fold images before the HTML parsing finishes, send a link HTTP header.
link header to load the image that serves as my IndieWeb photo and favicon. The header includes a priority hint so the browser starts downloading the resource right away.
link: </favicon.HASH.svg>; rel=preload; as=image; fetchpriority=high
Don’t count on the cache
The browser cache is a valuable tool to save bandwidth and improve page speed, but it’s not as reliable as many people seem to believe. Don’t focus too much on “repeat view” performance.
Out of privacy concerns, most browsers no longer re-use cached content across sites; refer back to the section on third-party content for more details. Privacy-conscious users (including all users using “private” or “incognito” sessions) will likely have their caches wiped between sessions.
Requesting a high number of cached resources can decrease performance of the cache, causing browsers to bypass the cache. The effect is especially pronounced on low-end phones and mechanical hard drives. Firefox calls this feature “Race Cache With Network”, documented in Mozilla Bug 1358038.
One way to help browsers decide which disk-cached resources to prioritize is to use immutable assets. Include the immutable directive in your cache-control headers, and cache-bust modified assets by changing their URLs. You can also keep your asset counts low by combining textual assets (e.g. CSS) and inlining small resources.
cache-control: max-age=31557600, immutable
Inline content
In addition to HTML, CSS is also a blocking resource. You could pre-load your CSS using a link header. Alternatively: if your compressed CSS is under a kilobyte consider inlining it in the <head> using a <style> element. Simply inlining stylesheets can pose a security threat, but the style-src CSP directive can mitigate this if you include a hash of your inline stylesheet sans trailing whitespace.
Consider inlining images under 250 bytes with a data: URI; that’s the size at which cache-validation requests might outweigh the size of the image. My 32-pixel PNG site icon is under 150 bytes and inlines quite nicely. On this site’s hidden service, it’s often the only image on a page (the hidden service replaces SVGs with PNGs; see the section on the Tor Browser). Inlining this image and the stylesheet allows my hidden service’s homepage to load in a single request, which is a welcome improvement given the round-trip latency that plagues onion routing implementations.
Transfer size and user flows
I find advice on page weight to be too simplistic. I prefer the perspective of what the industry calls “user flows”.
More than one way is available to locate a Web page within a set of Web pages except where the Web Page is the result of, or a step in, a process.
Here are some example flows that start with loading a homepage:note 4
-
A homepage has a link to a list of pages in a category. Your reader loads the homepage, navigates to the list page, and then navigates to the target page.
-
A homepage contains a link to a post which has “next post” and “previous post” links at the bottom. Your reader navigates to the post and clicks “next post” until they reach the target page.
-
A homepage has a “search” box. The reader searches for the target page and clicks a result on the result page.
Assume one of your readers has caching enabled, but their current cache is empty. They have a link to your homepage. Your reader should be able to perform at least two different flows to reach a target page, starting with navigating to your homepage. The total size transferred across their entire flow is the metric worth optimizing, not the weight of a single page. Set a performance budget for this flow. A “home, posts list, target page” flow can take a user from my homepage to this page using under 150 KiB.
Data is a scarce resource on metered connections; don’t waste it on unnecessary information. At least half the data transferred across the flow should be semantically-meaningful compressed markup. Try testing a “lite” version of a page with non-semantic markup removed: strip any <div> or <span> elements, or attributes that don’t have semantic value. Compare this “lite” page’s compressed markup size with the total download size of an actual page. Do this for every page across a flow.
I personally found this to be too much work. I skipped the creation of “lite” pages by removing non-semantic markup from my HTML: with the exception of utility classes that describe content rather than structure, my markup is made of semantically-relevant POSH, ARIA, Microdata, and microformats classes.note 5
Core Web Vitals aren’t enough
Download size matters, especially on metered connections. There’s no shortage of advice concerning minimizing this easy-to-understand metric. Unfortunately, it alone doesn’t give us the full picture: download size is not the exact same thing as time taken to deliver useful content to users.
Google’s answer to this problem is “Core Web Vitals” containing metrics such as the Speed Index. These metrics aren’t useless, but they are incredibly naive: they only take into account user-perceivable speed with an emphasis on user engagement, placing too little emphasis a page’s actual resource use. Plenty of other factors exist.
SpeedIndex is based on the idea that what counts is how fast the visible part of the website renders. It doesn’t matter what’s happening elsewhere on the page. It doesn’t matter if the network is saturated and your phone is hot to the touch. It doesn’t matter if the battery is visibly draining. Everything is OK as long as the part of the site in the viewport appears to pop into view right away.
Of course, it doesn’t matter how fast the site appears to load if the first thing the completed page does is serve an interstitial ad. Or, if like many mobile users, you start scrolling immediately and catch the ‘unoptimized’ part of the page with its pants down.
There is only one honest measure of web performance: the time from when you click a link to when you’ve finished skipping the last ad.
Everything else is bullshit.
Round trips
This sub-section is overkill for most use-cases.
A supplementary metric to use alongside download size is round trips. Estimate the number of bytes and round-trips it takes to do the following:
- Begin downloading the final blocking resource
- Finish downloading all blocking resources
- Finish downloading two screenfuls of content
- Finish downloading the full page.
Understanding round-trips requires understanding your server’s approach to congestion control.
Historically, TCP congestion control approaches typically set an initial window size to ten TCP packets and grew this value with each round-trip. Under most setups, this meant that the first round-trip could include 14.6 kilobytes. The following round-trip could deliver under thirty kilobytes.note 6 Try to ensure that all non-markup blocking resources and your document’s <head> fit within this 14.6 kilobyte budget.
Nowadays, servers employ BBR-based congestion control. It allows for regular “spikes” in window size, but the initial window size is still small. Find more details in the slides from TCP and BBR (application/
HTTP/3 uses QUIC instead of TCP, which makes things a bit different; the important thing to remember is that user agents should be aware of all blocking resources before finishing the earliest possible round-trip.
The golden kilobyte
One of the benefits of HTTP/2 and HTTP/3 is multiplexing: multiple resources can download over a single connection. Try to initiate downloads for blocking resources as soon as possible.
A TCP packet is 1460 bytes. Your first TCP packet will be partly taken up by a stapled TLS certificate, leaving you with under one kilobyte to work with.note 7 Make good use of this golden kilobyte; most or all of it will likely be taken up by HTTP headers.note 8 Ideally, the first kilobyte transferred should inform the client of all blocking resources required, possibly using preload directives; all of these resources can then begin downloading over the same multiplexed HTTP/2 connection before the current round-trip finishes! Note that this works best if you took my advice to avoid third-party content.
Apply these strategies in moderation. Including extra preload directives in your document markup might not help as much as you think, since their impact on page size could negate minor improvements. Micro-optimizations have diminishing returns; past a certain point, your effort is better spent elsewhere.
Layout shifts
Loading content of unknown dimensions, such as images, can create layout shifts; the WICG’s Layout Instability API describes the phenomenon in detail. Avoid layout shifts by including dimensions in HTML attributes. The simplest way to do so is by including unitless width and height values, but the style attribute could work too. I recommend staying away from the style attribute, or at least selectively allowing its use with the style-src-attr CSP directive.
Other server-side tweaks
In-depth server configuration is a bit out of scope, so I’ll keep each improvement brief.
Compression—especially static compression—dramatically reduces download sizes. My full-text Atom feed is almost a megabyte, but the Brotli-compressed version is under one-quarter of that size. Caddy supports this with a precompressed directive; Nginx requires the ngx_brotli module for Brotli compression.
When serving many resources at once (e.g., if a page has many images), HTTP/2 could offer a speed boost through multiplexing; use it if you can, but expect many clients to only support HTTP/1.1. HTTP/3 is unlikely to help textual websites much, so run a benchmark to see if it’s worthwhile.
Consider caching static assets indefinitely with a year-long duration in their cache-control headers, possibly with an immutable parameter. If you have to update a static asset, cache-bust it by altering the URL. This approach should eliminate the need for an etag header on static assets.
Using OCSP stapling eliminates the need to connect to a certificate authority, saving users a DNS lookup and allowing them to instead re-use a connection.
Consider the trade-offs involved in enabling 0-RTT for TLS 1.3. On one hand, it shaves off a round-trip during session resumption; on the other hand, it can enable replay attacks. 0-RTT shouldn’t be too unsafe for idempotent GET requests of static content. For dynamic content, evaluate whether your backend is vulnerable to replay attacks described in appendix E.5 of the spec.
Against lazy loading
Lazy loading may or may not work. Some browsers, including Firefox and the Tor Browser, disable lazy-loading when the user turns off JavaScript. Turning it off makes sense because lazy-loading, like JavaScript, is a fingerprinting vector. Specifically, it identifies idiosyncratic scrolling patterns.
Loading is only deferred when JavaScript is enabled. This is an anti-tracking measure, because if a user agent supported lazy loading when scripting is disabled, it would still be possible for a site to track a user’s approximate scroll position throughout a session, by strategically placing images in a page’s markup such that a server can track how many images are requested and when.
loading attribute
If you can’t rely on lazy loading, your pages should work well without it. If pages work well without lazy loading, is it worth enabling?
The scope of this article is textual content supplemented by images. In that context, I don’t think lazy loading is worthwhile because it often frustrates users on slow connections. I think I can speak for some of these users: mobile data near my home has a number of “dead zones” with abysmal download speeds, and my home’s Wi-Fi repeater setup used to result in packet loss rates surpassing 60% (!!).
Users on poor connections have better things to do than idly wait for pages to load. They might open multiple links in background tabs to wait for them all to load at once, and/or switch to another task and come back when loading finishes. They might also open links while on a good connection before switching to a poor connection. For example, I often open several links on Wi-Fi before going out for a walk in a mobile-data dead-zone. A Reddit user reading an earlier version of this article described a similar experience riding the train.
Unfortunately, pages with lazy loading don’t finish loading off-screen images in the background. To load this content ahead of time, users need to switch to the loading page and slowly scroll to the end to ensure that all the important content appears on-screen and starts loading. Website owners shouldn’t expect users to have to jump through these ridiculous hoops.
Against speculative pre-loading
Update : I’ve updated my stance on this. If you use the Speculation Rules API, preloading will obey user preferences in a standard cross-site way.
A common objection to my case against lazy-loading is that users may be more likely to click a link than scroll to the end, so pages should prioritize pre-loading the link. Pre-loading a page’s essential resources is fine. Speculatively pre-loading content on separate pages isn’t.
Many users with poor connections also have capped data, and would prefer that pages don’t decide to predictively load many pages ahead-of-time for them. The overlap between these two groups grows especially pronounced as data cap overages trigger throttling; this is enough to trigger a seasonal pattern in Japan.
Some go so far as to disable this behavior to avoid data overages. Savvy privacy-conscious users (including Tor Browser users) also generally disable speculative pre-loading since pre-loading behavior is fingerprintable.
Users who click a link choose to download its contents, within a reasonable size limit. Loading pages that a user hasn’t navigated to is making a choice for that user. I encourage adoption of “link” HTTP headers to pre-load essential and above-the-fold resources when possible, but doing so does not resolve the issues with lazy-loading: the people who are harmed by lazy loading are more likely to have pre-fetching disabled.
Moreover, determining the pages to prioritize for speculative pre-loading typically requires analytics and/or A/B testing. Enrolling users in a study (e.g. by collecting information about their behavior) without prior informed consent in terms they fully understand demonstrates a disrespect for their autonomy. Furthermore: analytics typically represent all users equally, when developers should be giving disproportionate attention to marginalized users (e.g., disabled users). The convenience of the majority should not generally outweigh the needs of the minority. Many marginalized groups don’t wish to broadcast the fact that they have special needs, so don’t rely on being able to figure out who’s whom.
Can’t users on poor connections disable images?
I have two responses:
-
If an image isn’t essential, don’t include it in the page. If an image is essential, assume sighted users want to see it.
-
Yes, users could disable images. That’s their choice. If your page uses lazy loading, you’ve effectively (and probably unintentionally) made that choice for a large number of users.
Nonetheless, expect some readers to have images disabled. Refer to the “Beyond alt-text” section to see how to best support this case.
Related issues
Pages should finish making all GET network requests while loading. This makes it easy to load pages in the background before disconnecting. I singled out lazy-loading, but other factors can violate this constraint.
One example is pagination. It’s easier to download one long article ahead of time, but inconvenient to load each page separately. Displaying content all at once also improves searchability. The single-page approach has obvious limits: don’t expect users to happily download a single-page novel.
Another common offender is infinite-scrolling. In addition to requiring JavaScript, infinite-scrolling also makes it difficult for readers to find their old place upon re-visiting a page. This creates harsh consequences for accidental navigation. WordPress documentation lists more problems with infinite scrolling.note 9
A hybrid between the two is paginated content in which users click a “load next page” link to insert the next page at the end of the current page (typically using “dynamic content replacement”). It’s essentially the same as infinite scrolling, except additional content is loaded after a click rather than by scrolling. This is only slightly less bad than infinite scrolling; it still has the same fundamental issue of allowing readers to lose their place.
I’ve discussed loading pages in the background, but what about saving a page offline (e.g. with Ctrl + s)? While lazy-loading won’t interfere with the ability to save a complete page offline, some of these related issues can. Excessive pagination and inline scrolling make it impossible to download a complete page without manually scrolling or following pagination links to the end.
xkcd comic: infinite scrolling

Infinite-scroll means that accidental navigation to a link results in losing your place. From xkcd
Toggle comic transcript
Comic transcript
Megan stands at a desk, touching a book gingerly. Cueball stands behind her.
- Cueball
- Why are you turning the pages like that?
- Megan
- If I touch the wrong thing, I’ll lose my place and have to start over.
- Caption below the panel
- If books worked like infinite-scrolling webpages
Long-page performance
Deferring network requests is a bad idea, as established in the previous “Against lazy loading” section. There are other ways to improve large-page performance.
An alternative to the loading attribute that I do recommend is the decoding attribute. I typically use decoding="async" so that image decoding can be deferred.
CSS containment
Long pages with many DOM nodes may benefit from CSS containment, a more recently-adopted part of the CSS specification.note 10
CSS containment allows authors to isolate sub-trees of the DOM. This lets browsers make more informed optimizations: they can delay painting off-screen content or reduce re-calculations when isolated nodes change. Combined with a property like content-visibility, it enables browsers to defer all rendering of less essential below-the-fold content.
content-visibility: autois a more complex directive thancontent-visibility: hidden; rather than being similar todisplay: none, it adaptively hides/displays an element’s contents as they become relevant to the user. It also doesn’t hide its skipped contents from the user agent, so screen readers, in-page search, and other tools can still interact with it.
content-visibility: auto
Leveraging containment and content-visibility is a progressive enhancement, so there aren’t any serious implications for older browsers. I use content-visibility to defer rendering off-screen entries in my archives. Doing so allows me to serve long archive pages instead of resorting to pagination, with page-length limited only by download size. In my tests using Lighthouse with Chromium Devtools’ simulated CPU throttling,note 11 this article rendered faster with containment-enabled CSS than without any custom stylesheets at all.
Using content-visibility for content at the end of the page is relatively safe. Using it for content earlier in the page risks introducing minor layout shifts and scrollbar-jumping. Eliminate the layout shifts by calculating a value for the contain-intrinsic-size property. Calculating ‘contain-intrinsic-size’ for ‘content-visibility’, by , is a comprehensive guide to calculating intrinsic size values. The scrollbar is less likely to jump around noticeably on extra-long pages, so sufficient page-length could let you get away with setting contain-intrinsic-size to a rough estimate.
Performance of assistive technologies
presentation The intersection of performance and accessibility describes how computing the accessibility tree can be expensive if a page has too many DOM nodes and custom elements. Browsers use complex heuristics to determine which elements to report, to reduce the size of the accessibility tree. Now that all major browsers are moving to multi-process architectures, some browser components interface with assistive technology (AT) in a separate process. Data about the page’s semantics needs to cross process boundaries, incurring additional overhead.
Re-calculating nodes in the accessibility tree can create small delays for user interaction. These delays add up, causing the accessibility tree to fall out-of-sync with the actual page state. In extreme cases, an out-of-control accessibility tree may crash the AT. Moreover, speech synthesizers may be slow to start speaking when the CPU is under load. Delayed speech synthesis is incredibly annoying because it tends to omit words while “warming up”.
When pages grow long, keep performance in check by doing the following:
-
Prefer semantic HTML over custom elements. The browser’s accessibility-tree-generation and element-filtering is optimized for semantic HTML; it has to do more guesswork to decipher custom elements.
-
Avoid scripts that delay user-input or cause complex DOM mutations. These will introduce delays that can cause significant AT usability issues.
-
Remember that CSS can impact the accessibility tree. Avoid using scripts to alter properties such as
displayandvisibility. -
Test with screen readers on underpowered hardware. Examples include old entry-level Android phones and netbooks with aggressive thermal throttling.
Old browsers
People do not use your site exclusively with the latest stable versions of Chrome, Firefox, or Safari. If you use metrics, they will be biased against users who avoid your site due to incompatibilities.
Old browsers in use
Plenty of reasons exist for using older versions of each of the mainstream browsers:
- Firefox
- In addition to Firefox’s “Stable”, “Beta”, and “Nightly” channels, Firefox includes an “Extended Support Release” (ESR). Firefox ESR receives only bugfixes and major security patches for over one year. It’s the default browser in Debian and the basis for the Tor Browser. In other words: if you want people to be able to browse your site anonymously (i.e. with the Tor Browser), you need to support Firefox ESR versions for over 15 months after their release (sometimes longernote 12). If that wasn’t enough: the latest version of KaiOS uses Firefox 84, while older versions (still being sold in 2022!) use Firefox 49.note 13
- Safari and WebKit
- On Linux, WebKitGTK powers various browsers, RSS readers, and in-app browsers. WebKitGTK versions are limited by a distribution’s release model; LTS distributions will not have the shiniest new WebKit features. Safari versions are similarly limited by iOS and macOS versions. For instance, the iPhone 7 will not be able to run iOS 16 or Safari 16, just four years after it was discontinued; it’ll only receive occasional security patches for Safari 15.x. The only way for iPhone-7-and-earlier users to use Safari 16+ features is to buy a new phone. Expecting users to buy a new device every few years just to display a webpage needlessly contributes to the rampant consumerism and throw-away culture in the consumer electronics industry.
- Chromium
- Google Chrome’s “Extended stable” channel releases half as often as its “Stable” channel. Moreover, Chromium is the basis for QtWebEngine, the Web engine of the Qt UI toolkit. QtWebEngine powers a host of Web browsers: Qutebrowser, Falkon, Nyxt, Angelfish, Otter Browser, and others. Like WebKit2GTK, QtWebEngine powers various RSS readers and in-app browsers. The latest version of Qt typically includes a QtWebEngine several versions behind upstream Chromium, and most distributions don’t ship the latest version of Qt. Finally, Android’s Chromium-based WebView implementations are still sometimes locked to a vendor’s abandoned version of Android and woefully out of date; in-app browsers are often even worse, sometimes shipping a version of Chromium that’s years old.
- Opera
- Opera switched away from its in-house Presto browser engine a few years ago, in favor of becoming a Chromium fork. However, Opera Presto is still being kept alive by Opera Mini. Opera Mini’s “extreme” mode uses a proxy server to render pages; that server runs Opera’s Presto rendering engine, which hasn’t added new Web standards in years.
How to support old browsers
I recommend testing with a pre-2013 version of WebKit, as those WebKit versions are ancestors to both Chromium and Safari. Old versions of Opera and Firefox are still available for download. Obviously, I wouldn’t recommend using these browsers outside of a heavily sandboxed environment (e.g. a confined VM) unless you disable unnecessary features and limit their use to testing.
Always use progressive enhancement: everything besides your semantic markup and the occasional legacy image format should be an optional enhancement. Test with CSS, scripts, new image formats, etc. disabled.
Restrict markup to the subset of the WHATWG’s HTML Living Standard that also appears in the W3C’s HTML 5.1 standard. This should provide a slower-moving base than the raw Living Standard that’s also friendlier to older browsers. I don’t recommend referencing the W3C’s HTML 5.1 standard directly, since the Living Standard has since made several important clarifications, corrections, and removals.note 14
CSS offers multiple equivalent ways to do the same thing; prefer older versions when possible. A non-exhaustive list of ways to make stylesheets work in older browsers:
-
Use
emunits rather than the more convenientrem -
Avoid CSS variables and custom properties; keep track of values by using increments, or use a post-processor to replace references to variables.
-
Use the
@supportsat-rule to progressively replace an older feature with a newer one. -
Explicitly define the
displayproperty for thehiddenattribute, for browsers that don’t supporthidden.
When in doubt: Can I Use and MDN’s browser compatibility data are excellent resources to track feature support across all the mainstream browser engines.note 15 Feel free to go wild when adding strictly-optional features.
The Tor Browser
Many people use Tor out of necessity. On Tor, additional constraints apply.
Constraints of the Tor Browser
Tor users are encouraged to set the Tor Browser’s security settings to “safest”. This disables scripts, MathML, remote fonts, SVG images, and other unsafe Firefox features. If your site has any SVG images, the Tor browser will download these just like Firefox would (to avoid fingerprinting) but will not render them.
If you must use scripts, ensure that they perform well with just-in-time (JIT) compilation disabled. The Tor Browser’s “safer” mode, iOS Lockdown mode, and Microsoft Edge’s “enhanced” security mode all disable JIT compilation by default.note 16
Additionally, hopping between nodes in Tor circuits incurs latency, worsening the impacts of requiring multiple requests and round-trips. Try to minimise the number of requests to view a page.
If you use a CDN or some overcomplicated website security stack, make sure it doesn’t block Tor users or require them to enable JavaScript to complete a CAPTCHA. Tor Browser users are supposed to avoid fingerprinting vectors like JS and browser extensions, so requiring a JavaScript-
Tor users are unable to leverage media queries or client-hints to signal special needs. Pages need to be as accessible as possible by default, as per the “inclusive by default” directive outlined earlier. This should be a given, but it’s doubly important when serving fingerprinting-averse readers.
Hidden services
To go above and beyond, try mirroring your site to a Tor hidden service to reduce the need for exit nodes. Mirroring allows you to keep a separate version of your site optimized for the Tor browser.
Normally, optimizing specifically for a given user agent’s quirks (especially in a separate version of a website) is a bad practice; however, the Tor Browser is a special case because there’s no alternative available: Tor users should all use the same browser to avoid standing out. Sometimes, the Tor Browser pretends to have Firefox’s capabilities: progressive enhancement and graceful degradation won’t work when a browser lies about its functionality.
For example, my website’s clearnet version uses some SVG images. Some browsers can’t handle a given image format. The typical solution is to use a <picture> element containing <source> children of varying formats and a fallback <img> element using a legacy image format.
The Tor browser will download whichever format Firefox would, rather than whichever formats it actually supports. A <picture> element containing an SVG and a raster fallback won’t help: the Tor browser will avoid fingerprinting by selecting the SVG format, not a fallback format. The image will not be rendered, so users will have downloaded the image only to see a white box.
I address the issue by not using any SVG images on my hidden service.
In-page search
In-page search (e.g., using Ctrl + f) has been a basic feature in document readers well before browsers, and continues to be an essential feature today.
Searchability is a good reason to prefer conveying information textually, when possible: video (especially without accurate captions), pictures of text, etc. aren’t so easily searchable.
Web pages that hide content behind “show content” widgets are difficult to search through: users need to toggle “show content” for each item they wish to search. Often, in-page search highlights are hidden; Reddit’s atrocious redesign is a serious offender. If you need to hide some content for performance reasons, I described a less hostile way to do so in the “Long-page performance” section.

Searching for the word “good” before and after a “see more” link is clicked. Both situations show a match, but only one of them allows us to view the match. Both screenshots are from the Reddit redesign.
The importance of proofreading
Correct, consistent spelling is important to readers who use search. In-page search doesn’t currently pick up misspelled words. If in-page search implementations develop such a feature, some users may wish to sometimes turn it off; even Google Search implemented a “verbatim” mode for exact matches.
Moreover, some search implementations (such as the one built into Firefox) support case-sensitive matching. Inconsistent capitalization of proper nouns, acronyms, and initialisms can make searching difficult.
Problematic overrides
Search is so essential to some users’ ability to navigate that some desktop users enable “type-ahead” search, to automatically begin a search upon typing multiple characters.note 17 If you ignored my advice to avoid JavaScript, at least think twice before using it to define custom keyboard shortcuts which interfere with this type of functionality. I singled out type-ahead search, but there are countless other examples of uncommon keyboard behavior that JavaScript overrides interfere with.
Another problematic override is scroll-behavior. Enforcing smooth-scrolling (e.g., with the scroll-behavior CSS property) can interfere with the use of in-page search by slowing down jumps between matches. Rapidly darting around the page with smooth scrolling can cause motion sickness. Simply relying on users to override default behaviors violates the “inclusive by default” directive I encourage, since user preferences are fingerprintable and shift responsibility away from developers.
There’s a complex solution to turn off smooth scrolling for un-focused elements, but it doesn’t address separate issues such as anchor-link navigation.
About fonts
I recommend setting the default font to sans-serif. system-ui causes issues among readers whose system fonts don’t cover your website’s charset.
If you really want, you could use serif instead of sans-serif; however, serif fonts tend to look worse on low-res monitors. Not every screen’s DPI has three digits. Accommodate users’ default zoom levels by keeping your font size the same as most similar websites.
To ship custom fonts is to assert that branding is more important than user choice. That might very well be a reasonable thing to do; branding isn’t evil! That being said, textual websites in particular don’t benefit much from branding. Beyond basic layout and optionally supporting dark mode, authors generally shouldn’t dictate the presentation of their websites; that should be the job of the user agent. Most websites are not important enough to look completely different from the rest of the user’s system.
A personal example: I set my preferred browser font to sans-serif, and map it to my preferred font in my computer’s fontconfig settings. Now every website that uses sans-serif will have my preferred font. Sites with sans-serif blend into the users’ systems instead of sticking out.
But most users don’t change their fonts…
The “users don’t know better and need us to make decisions for them” mindset isn’t without merits; however, in my opinion, it’s overused. Using system fonts doesn’t make your website harder to use, but it does make it smaller and stick out less to the subset of users who care enough about fonts to change them. This argument isn’t about making software easier for non-technical users; it’s about branding by asserting a personal preference.
Moreover, third-party fonts may not always work. The Tor Browser’s “Safer” and “Safest” modes and iOS 16’s “Lockdown Mode” disable them. Content-blockers like Firefox Focus and uBlock Origin prominently expose remote-font toggles. If you ship remote fonts, you’ll need to test your site with remote and system fonts.
Stylesheet overrides aren’t an excuse
It’s not a good idea to require users to automatically override website stylesheets to see their preferred fonts. Doing so would break websites that use fonts such as Font Awesome to display vector icons. We shouldn’t have these users constantly battle with websites the same way that many ad- and script-blocking users (myself included) already do when there’s a better option.
That being said, many users do actually override stylesheets. We shouldn’t require them to do so, but we should keep our pages from breaking in case they do. Pages following this article’s advice will probably work perfectly well in these cases without any extra effort.
Font fingerprinting concerns
Some people raised fingerprinting concerns when I suggested using the default “sans-serif” font. Websites could see which font this maps to in order to identify users.
You can’t do font enumeration or accurately calculate font metrics without JavaScript. Since text-based websites that follow these best-practices don’t send requests after the page loads and have no scripts, they shouldn’t be able to fingerprint via font identification.
Other websites can still fingerprint via font enumeration using JavaScript. They don’t need to stop at seeing what sans-serif maps to: they can see available fonts on a user’s system,note 18 the user’s canvas fingerprint, window dimensions, etc. Some of these can be mitigated by Firefox’s protections against fingerprinting, but these protections understandably override user font preferences.
Ultimately, surveillance self-defense on the web is an arms race full of trade-offs. If you want both privacy and customizability, the web is not the place to look; try Gemini or Gopher instead.
Zoom and font size
Browsers allow users to zoom by adjusting size metrics. Additionally, most browsers allow users to specify a minimum font size. Minimum sizes don’t always work; setting size values in px can override these settings.
In your stylesheets, avoid using px where possible. Define sizes and dimensions using relative units (preferably em). Exceptions exist for rare items that that shouldn’t scale with zoom (e.g. decoration, minimum margins).note 19
font: 107.5%/1.5 sans-serif;
Beyond alt-text
Expect some readers to have images disabled or unloaded. Examples include:
-
Blind readers.
-
Users with metered connections: sometimes they disable all images, and other times they only disable images surpassing a size.note 20
-
People experiencing packet loss who fail to download some images.
-
Users of textual browsers.
Accordingly, follow good practices for alt-text:
-
Concisely summarize the image content the best you can, without repeating the surrounding content.
-
Images should usually have alt-text under 100 ch.note 21 Save longer descriptions for a caption or
aria-. Exceptions exist; this is just a weak norm. If longer descriptions elsewhere aren’t an option, disregard this advice and make alt-text as long as it needs to be.describedby -
Don’t include significant information that isn’t present in the image; I’ll cover how to handle supplementary information in the next subsections.
The WAI provides some guidelines in An alt Decision Tree. It’s a little lacking in nuance, but makes for a good starting point. Remember that guidelines and “good practices” always have exceptions.
Alt text isn’t just for blind readers; sighted readers who can’t load an image will see alt-text in its place. This alt text might be confined to the image container, so small images should have shorter alt text.note 22
Putting images in context
Alt text should be limited to describing content of the image. It lacks context. To make things worse, images can contain a great deal of information. Sighted people can “filter” this information and find areas to focus on; alt text should capture this detail. However, sighted users’ understanding of this detail can be informed by surrounding less-essential detail.
Blind users might struggle to view images in context; they can’t easily scan the text before and after an image non-linearly if there’s no semantic connection between them. Charles McCathieNevile described this experience by comparing screen reading to reading through a drinking straw.
Being sighted and loading images can introduce issues of its own. Sometimes, sighted readers might focus on the wrong part of an image. How can you give readers the missing context and tell them what to focus on?
The best solution comes in two parts:
- Before the image, supply context that prepares readers for what to expect.
- After the image, describe your interpretation of important details.
This is somewhat similar to the way most students in primary and secondary schools are taught to cite evidence in essays. On that note: remember that these are weak norms, not rules. Deviate where appropriate, just as students should as they learn to write.
Figures
A figure is any sort of self-contained information that is referenced by—but somewhat distinct from—body content. Items that make for good figures are often found in floating blocks of print material.
Consider using a <figure> element when employing the previous section’s two-part strategy. Place one of the two aforementioned pieces of information in a <figcaption>; the caption can come before or after the image.
Figures aren’t just for images; they’re for any self-contained referenced content that’s closer to the surrounding body than an <aside>. Some example items that could use a caption:
- Blockquote
- Captioned with a citation
- Code snippet
- Captioned with its purpose or a link to the larger file from which the snippet was borrowed
- Mathematical notation
- Sometimes captioned with a brief explanation of its behavior, purpose, or significance. Remember to add alt-text.
Figures and captions have loose guidelines, and nearly everything I said on the matter is full of exceptions. A figure need not have a caption, but the majority benefit from one. It need not contain a single main element, but most probably should.
I personally try to maintain the flow of an article even if its figures and captions are completely removed or moved to an appendix. A figure is a “self-contained” block: user agents may re-position figure captions relative to the main figure content, or move the entire figure elsewhere; this is especially common in reading-mode implementations. The HTML specification explicitly notes this behavior; Pandoc’s HTML-to-LaTeX conversion and PrintFriendly are examples of software that moves figure elements around to improve pagination.
When a
figureis referred to from the main content of the document by identifying it by its caption (e.g., by figure number), it enables such content to be easily moved away from that primary content, e.g., to the side of the page, to dedicated pages, or to an appendix, without affecting the flow of the document.If a
figureelement is referenced by its relative position, e.g., “in the photograph above” or “as the next figure shows” then moving the figure would disrupt the page’s meaning. Authors are encouraged to consider using labels to refer to figures, rather than using such relative references, so that the page can easily be restyled without affecting the page’s meaning.
figure element
Image transcripts
Some images contain text. I describe best practices for preparing pictures of text in the “Pictures of text” section. Only use pictures of text if the visual appearance of the text is an essential part of what you wish communicate. If the content of the text is also important, include a transcript.
Image transcripts aren’t just useful for the visually impaired; they also help users relying on machine-translation, since translation tools rely on textual content. These users won’t read alt-text; have an alternative way to discover a transcript.
If the image is a screenshot of text from a website, link to that website to allow users to read its contents in context; this can serve as an “image transcript” of sorts.
A longdesc attribute used to be another way to reference an image transcript. The longdesc attribute contained a hyperlink (often an anchor link) to a location with more information about an image. This attribute has been obsoleted in the HTML Living Standard.
The recommended way to link to a transcript is by hyperlinking the image (i.e., wrapping it with <a>) or semantically grouping the image with its transcript. Put a short summary in the alt-text, and mention the availability of a transcript in a visible caption.
A StackOverflow thread about comic transcripts outlines a good approach to semantically grouping images and transcripts, and my approach is similar. I group an image, alt-text, and caption in a <figure> element and follow it with a transcript in a <details> element. I use aria- to semantically link the figure and the transcript.note 23
An image, alt-text, figure caption, and transcript combine to form a complex relationship that should be grouped together in a single landmark. I put all three inside a <section> with a heading, and give the group an aria-label that indicates the presence of the three sub-elements. Using a section landmark ensures that the figure and caption remain together as a single unit. The html code for the xkcd comic earlier in the page is a representative example.
<section aria-label="comic, caption, and transcript">
<h4>Infinite scrolling</h4>
<figure>
<img src="SRC"
aria-describedby="transcript-xkcd-1309"
alt="Comic: infinite-scrolling books require
careful page-turns to avoid losing the page.">
<figcaption>
Infinite-scroll means that accidental navigation
to a link results in losing your place.
</figcaption>
</figure>
<details>
<summary>Toggle transcript</summary>
<div id="transcript-xkcd-1309">
<p>Megan stands at a desk, touching a book
gingerly. Cueball stands behind her.</p>
<dl>
<dt>Cueball</dt>
<dd>Why are you turning the pages like that?</dd>
<dt>Megan</dt>
<dd>If I touch the wrong thing, I’ll lose my
place and have to start over.</dd>
<dt>Caption below the panel</dt>
<dd>If books worked like infinite-scrolling
webpages</dd>
</dl>
</div>
</details>
</section>
About custom colors
Always remember that any color palette you define in your stylesheets is merely a suggestion. Any colors you don’t define could fall back to arbitrary defaults; all colors you define could be overridden by the user agent or operating system.
Default colors
Some users’ browsers set default page colors that aren’t black-on-white. For instance, Linux users who enable GTK style overrides might default to having white text on a dark background. Websites that explicitly set foreground colors but leave the default background color (or vice-versa) end up being difficult to read. The same phenomenon occurs on pages with text foregrounds with image backgrounds.
A second opinion: describes this in more detail in A Web Colours Problem. In short: when setting colors, always set both the foreground and the background color. Don’t set just one of the two.
Chris also describes the importance of visited link colors in Visited Links Usability.
Example unreadable palette
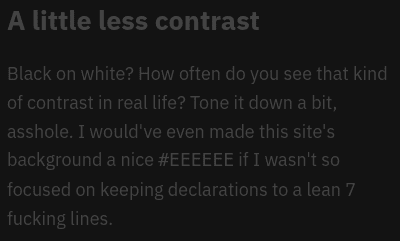
This is an unreadable screenshot of Better Motherfucking Website. I had set my browser foreground and background colors to white and dark gray, respectively. The website overrode the foreground colors while assuming that everyone browses with a white background.
Toggle screenshot transcript
Screenshot transcript
A little less contrast.
Black on white? How often do you see that kind of contrast in real life? Tone it down a bit, asshole. I would’ve even made this site’s background a nice #EEEEEE if I wasn’t so focused on keeping declarations to a lean 7 fucking lines.
Color overrides and accessibility
Even if you set custom colors, ensure that the page is compatible with color overrides: elements shouldn’t be distinguished solely by foreground and background color. Technique C25 for the Web Content Accessibility Guidelines (WCAG) 2.2 describes how doing so can meet the WCAG 2.2’s Success Criterion 1.4.8. Specifically, it describes using default colors in combination with visible borders. The latter helps distinguish elements from surrounding content without relying on a custom color palette.
This page’s canonical location is an example application of Technique C25 (and the related Technique G148). It only uses non-default colors when a user agent requests a dark color scheme (using the prefers-color-scheme CSS media query; see the next subsection) and for lightening borders. Any image with a solid background may match the page background; to ensure that their dimensions are clear, I surrounded them with borders. Most browsers will render these borders with the default foreground color, which should be visually distinct from the background. I included borders and/or horizontal rules to break up some sections, since heading-based delineation is either unavailable or insufficient for them. When overriding color schemes, the page layout remains clear.
Color overrides go well beyond simple foreground and background color changes. Windows High Contrast Mode (WHCM) is perhaps the best example. WHCM makes advanced modifications to color palettes: it colors elements with a user-specified palette, all according to semantic markup while ignoring ARIA overrides.note 24
WHCM leads the standardization process for the forced-colors CSS media feature, but it isn’t the only implementation of the underlying idea. If you navigate to about:preferences in Firefox and activate the Colors button in the “Language and Appearance” section, you’ll be presented with the option to override website palettes with your own default colors.
Not all approaches completely discard a designer’s specified color palette. The CSS Working Group is working on a specification for stylesheet processing in CSS Color Adjustment Module Level 1. The Chromium team’s in-progress auto dark mode will use this specification to darken websites globally. Websites can opt out with the color-scheme property, but they really shouldn’t have to: stylesheets should be robust enough to handle re-coloring.
Win HCM is a collection of user defined color themes that overwrite your definitions in CSS.
It’s not about design but readability.
Some stuff will disappear in Win HCM, some won’t. Best advice is to use semantic HTML to keep things visible.
You can use transparent
outlineto keep things visible like focus indicators and surface boundaries or usecurrentto maintain SVGColor fillcolors in Win HCM.You can use a special media query combined with special CSS color keywords to give elements the user defined colors.
Dark themes
If you do explicitly set colors, please also include a dark theme using a media query: @media (prefers-color-scheme: dark). For more info, read the prefers-color-scheme docs on MDN. Dark themes are helpful for readers with migraines, photosensitivity (like me!), or dark environments.
If you include a theme-color directive in your document <head>, then recent browsers will automatically switch their default stylesheets to dark-mode. Unfortunately, some older browsers (like Firefox-ESR) don’t support this directive, and WebKit’s default dark stylesheet has unreadable links. WebKit versions in the wild are often out of date, so a fixed stylesheet would need to be out for many years before I would consider using default dark stylesheets.

CSS filters such as invert are expensive to run, so use them sparingly. Simply inverting your page’s colors to provide a dark theme could slow it down or cause a user’s fans to spin.
Darker backgrounds draw less power on devices with OLED screens; however, backgrounds should never be solid black. White text on a black background causes halation, especially among astigmatic readers. Halation comes from the word “halo”, and refers to a type of “glow” or ghosting around words. There has been some experimental color research and plenty of anecdotal evidence from astigmatic users to support this.
This image is an approximation of what halation looks like, cropped from Essential Accessibility.

“Just disable dark mode” is a poor response to users complaining about halation: it ignores the utility of dark themes described at the beginning of this section.
If you can’t bear the thought of parting with your solid-black background, worry not: there exists a CSS media feature and client-hint for contrast preferences called prefers-contrast. It takes the parameters no-preference, less, and more. You can serve increased-contrast pages to those who request more, and vice versa. Check section 11.3 of the W3C Media Queries Level 5 specification for more information.
I personally like a foreground and background of #E9E9E9 and #191919, respectively. These shades seem to be as far apart as possible without causing accessibility issues: #191919 is barely bright enough to create a soft “glow” capable of minimizing halos among slightly astigmatic users, but won’t ruin contrast on cheap displays. I also support a prefers-contrast: less media query which lightens the background to #333.note 25
Use the Advanced Perceptual Contrast Algorithm
Color is a nuanced topic that deserves more attention than current guidelines give.
When setting colors, especially for a dark background, I recommend checking your page’s contrast using Accessible Perceptual Contrast Algorithm (APCA) values. You can do so in an online APCA checker (requires JavaScript) or Chromium’s developer tools (you might have to enable them in a menu for experimental preferences). I recommend using the web app.
The APCA takes several factors into account:
-
The human retina has few blue-sensitive cone cells, so blue appears “darker” than green and red. Yellow appears brightest.
-
Small, thin fonts are difficult to see and require greater contrast.
-
It’s possible to have too much contrast, especially for large/bold text (note that the APCA version built into Chromium does not yet take this into account).
Note that the APCA isn’t fully mature as of early 2022. Until version 3.0 of the WCAG is ready, pages that are required to comply with the WCAG should also conform to the contrast ratios described in the WCAG 2.2’s success criteria 1.4.3 (Contrast: Minimum, level AA) or 1.4.6 (Contrast: Enhanced, level AAA). This site’s dark-mode stylesheet is an example of a palette that conforms to both the WCAG 2.2 AAA contrast requirements and APCA recommendations.
What contrast algorithms don’t cover: over-saturation
Even if the APCA is much better than the WCAG’s current naive contrast algorithms, it still doesn’t account for all aspects of the relationship between perceptual contrast and color. Discussion no. 74 on the SAPC-APCA repository covers some shortcomings. For instance, the current APCA version does not account for the Helmholtz–Kohlrausch effect: highly-saturated colors appear “brighter” than de-saturated colors with the same brightness. Excessive perceptual brightness against dark backgrounds can trigger halation, eye-strain, and overstimulation.
Yellow may have great contrast on dark backgrounds, but vivid yellow and red can cause problems among people who deal with overstimulation; this includes many on the autism spectrum. wrote about the issue on the TPGi blog: Beyond WCAG: Losing Spoons Online.note 26
If you want to use significant amounts of “emergency colors” like yellow and red, de-saturate them so their color feels muted. This site’s dark theme uses very pale, washed-out yellow and violet for maximum contrast with minimal harshness.
Accounting for halation, overstimulation, and high-contrast needs is hard to do if you prioritize minute aesthetics before inclusivity.
Contrast under different conditions
Color palettes need to be effective for different types of vision deficiencies (e.g. color blindnesses) and screens. Color blindness is a far more nuanced topic than “the inability to see some colors”. describes his experience in Color blindness. Color blindness manifests in complex ways. Testing in grayscale is a great start, but it doesn’t account for all kinds of color vision deficiencies.
Different screens and display-calibrations render color differently; what may look like a light-gray on a cheap monitor could look nearly black on a high-end OLED screen. Try to test on both high- and low-end displays, especially when designing a dark color scheme.note 27
Color schemes should also look good to users who apply gamma adjustments. Most operating systems and desktop environments bundle a feature to reduce the screen color temperature at night, while some individuals may select a higher one in the morning.
Visible interactive semantics
Color is not used as the only visual means of conveying information, indicating an action, prompting a response, or distinguishing a visual element. (Level A)
A basic WCAG Level A requirement is for information to not be conveyed solely through color. Both the presence and type of interactivity need to be visually communicated by other means. Links should not look like buttons, and vice-versa.
In defense of link underlines
Some typographers insist that underlined on-screen text is obsolete,note 28 and that hyperlinks are no exception. I disagree.
Readers already expect underlined text to signify a hyperlink. Don’t break fundamental affordances for aesthetics. Underlines are also necessary to distinguish the beginnings and ends of multiple consecutive links, especially among color-blind users.

It’s impossible to discern the number of links in a sequence without some sort of separator. Whitespace alone isn’t sufficient.
Moreover, several parts of Making Content Usable for People with Cognitive and Learning Disabilities recommend underlining links.
Some users have trouble when controls have a different look, color, or shape than they have used before. For example, when links do not have underlines and blue or purple text some users will not know there is a link (even if this appears with focus).
This stance is not absolute. Users are familiar with very common design patterns, such as navigation bars and search results. Underlines are still preferable, but I find their absence less concerning in these cases.
Buttons versus links
Buttons are another type of interactive element. Users are accustomed to recognizing buttons by their visually distinct interactive region. While hyperlinks are only signified by color and a text underline, buttons are signified by a background-color change and/or a visible border. Do not conflate the two!
The purpose of a hyperlink is to navigate to a different location. If a button exists to do the same thing, it shouldn’t be a button; it should have both hyperlink semantics and presentation instead. Otherwise, the consequences of element activation are unclear.
Use a clear and recognizable design for controls. Make it clear what elements are controls and how to use them.
This includes:
- Using a common style on controls (for example, links being underlined).
- Using common design patterns on links and controls (for example, clicking on a link takes you to the page).
- Making the borders of controls clear. Links in text do not need borders if identified properly (for example, a help icon has a border).
- Making controls large enough so that users can click on it and not the item next to it.
- Ensuring items that are not clickable do not look like links or controls.
When this is not possible, provide instructions that explain how to use the control.
One key difference between buttons and links is the cursor appearance. Buttons should not turn the cursor into a “hand” or “pointer” icon. The article Some pointers on default cursors by covers both sides of the issue. Personally, I think it’s best to respect the convention of the browser and OS rather than break it.
Read more about the differences between buttons and links in Buttons vs. Links by .
Visible non-interactive semantics
In addition to offering ample non-interactive space, ensure that non-interactive and interactive regions are visually distinct. Avoid making interactive elements with many children.
GitHub’s mobile website is a serious offender; see this screenshot of the GitHub bug tracker for an example.
- The background region of the visible issue is interactive, and so are its contents.
- The header of the issues list has a non-interactive background that looks the same as the aforementioned interactive background.
- Visual appearance does not convey the difference between a button and a hyperlink: The “enhancement” link looks like a button
- The “enhancement” link points to a unique location, yet it loses its interactivity on narrow viewports with no visual change; tapping it navigates to a different location depending on viewport width.
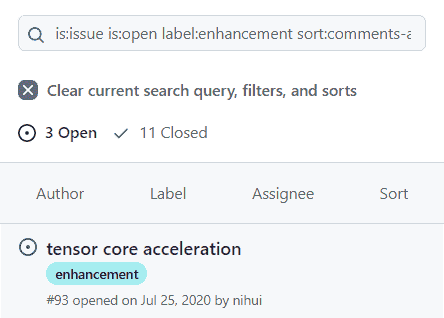
Someone using the GitHub issues interface for the first time will struggle to identify interactive regions and discern whether they trigger navigations or different actions.
Against focusable containers
Screen readers like iOS VoiceOvernote 29 fail to follow in-page links whose targets are not focusable. Designers often work around this by annotating link targets with the tabindex="-1" HTML attribute. This is a good idea when a link target is a heading or piece of phrasing content. Unfortunately, making large containers focusable ruins keyboard-navigability.
Normally, if you select some text in a page and press Tab, the tab-focusable element after the selected text will receive focus. However, if the selectable text is inside a focusable container—even a container with a negative tabindex—pressing Tab will move focus to the start of the container. If you’re reading this on a desktop browser, you can experience this first-hand: select some text in this paragraph and press Tab. Then, do the same in this snapshot of an excellent Smashing Magazine article.note 30

Two screenshots of the aforementioned Smashing Magazine article after I selected the title text, before and after pressing Tab. The focus moves backwards to the start of the container because the container is focusable. The focus should have moved to an element after the selected text.
This behavior is particularly frustrating on long pages. Imagine if pressing Tab took you to the start of this article!
Image optimization
Some image optimization tools I use:
pngquant- lossy PNG compression. Can reduce the size of the color palette.
gifsicle- Optimizes GIF images, static or animated. Supports many dithering options and advanced optimization options for animations.
didder- Offers more advanced dithering options than gifsicle and pngquant.
oxipng- Lossless PNG compression. It’s like a parallelized version of OptiPNG that also supports an implementation of ZopfliPNG compression
jpegoptim- Lossless or lossy JPEG compression. Note that JPEG is an inherently lossy format; the lossless features of
jpegoptimonly shrink the size of existing JPEG files by removing unnecessary metadata. cwebp- The reference WebP encoder; has dedicated lossless and lossy modes. Lossy WebP compression isn’t always better than JPEG, but lossless WebP consistently beats PNG.
avifenc- The reference AVIF encoder, included in libavif.note 31 AVIF lossless compression is typically useless, but its lossy compression is pretty unique in that it leans towards detail removal rather than introducing compression artifacts. Note that AVIF is not supported by Safari or most WebKit-based browsers. It also seems unsupported in Microsoft Edge.note 32
I put together a quick script to losslessly optimize images using these programs. For lossy compression, I typically use GNU Parallel to mass-generate images using different options before selecting the smallest image at the minimum acceptable quality. Users who’d rather avoid the command line while performing lossy compression can instead check out Squoosh, a JavaScript app that bundles WebAssembly-compiled encoders; I’ve heard good things about it.
You also might want to use the HTML <picture> element, using JPEG/PNG as a fallback for more efficient formats such as WebP or AVIF, but only if the size savings (or quality improvements at a similar size) are significant. More info is in the MDN <picture> docs
Most of my images will probably be screenshots that start as PNGs. My typical flow:
-
Re-size and crop the PNG. Convert to grayscale if color isn’t important.
-
Lossy compression with
pngquant -
Losslessly optimize the result with
oxipngand its Zopfli backend (slow) -
Also create a lossless WebP from the lossy PNG and a lossy WebP from the source image, using
cwebp. Pick the smaller of the two. -
Include the resulting WebP in the page, with a fallback to the PNG using a
<picture>element. -
Create a lossy AVIF image from the cropped full-color PNG, and include it in the
<picture>element if it’s smaller than the WebP. If color isn’t important, use the YUV400 color space. -
If the image is too light, repeat for a dark version of the image to display in response to a
prefers-color-scheme: darkmedia query.
In general, avoid loading images just for decoration. Only use an image if it has a clear purpose that significantly adds to the content in a way that text can’t replace, and provide alt-text as a fallback. Any level of detail that isn’t necessary for getting the point across should be removed by lossy compression and cropping.
If you want to include a profile photo (e.g., if your website is part of the IndieWeb and uses an h-card), I recommend re-using one of your favicons. Doing so should be harmless since most browsers will fetch and cache favicons anyway.
If you really want to take PNG optimization to the next level, try Efficient Compression Tool.
pngquant, and oxipng. It shrinks the image, turns it grayscale, reduces the color palette, and then applies lossless Zopfli compression.
convert ORIGINAL_FILE \
-resize 75% -colorspace gray -format png - \
| pngquant -s 1 12 - \
| oxipng -o max -Z --fix - --out OUTPUT_FILE
Breaking conventional wisdom
Some conventional wisdom for image compression doesn’t hold up when compressing this aggressively; for instance, I’ve found that extremely aggressive dithering and PNG compression of small black-and-white images consistently surpasses JPEG compression.
Most resources on image optimization recommend progressive rendering. I don’t recommend progressive rendering for below-the-fold images; if you optimize an image to just a few kilobytes, it should fully load in time. It’s not worth the overhead for resources of less than 20 kb.
These resources also encourage authors to include different image variants for different viewport sizes, screen resolutions, and pixel densities. They often skip the caveats:
-
Using different image files for different viewport sizes can cause the page to request more images as users re-size their window.
-
Sending requests dependent on viewport and display characteristics is a fingerprinting vector, allowing servers to identify users by these properties.
Rather than create separate lanes for different users, I prefer making the defaults as inclusive as possible. A single image should look good under a variety of downscaling algorithms. It should be as small as it can be without losing essential information.
It might seem odd to create a lossless WebP from a lossy PNG, but I’ve found that it’s often the best way to get the smallest possible image at the minimum acceptable quality for screenshots containing solid backgrounds.
Enforce image compression
The “Document Policy” HTTP header has experimental directives lossless-images-max-bpp and lossy-images-max-bpp. In this context, “bpp” refers to “bytes per pixel”; a 256-by-256 pixel image that’s 6.6 kilobytes large would have a “bpp” of 0.1. If it’s a lossy image, then sending lossy-images-max-bpp=0.1 would forbid the image from loading if it’s over 6.6 kilobytes in size.
Currently, these directives are disabled-by-default in Chromium; you can enable them by navigating to chrome://flags and toggling “Experimental Web platform features”. I don’t think these directives are perfect, but they are quite useful.
Dark image variants
Bright images on an otherwise dark page distract readers, especially readers like me with ADHD. The human iris adjusts to average amounts of light; an object far brighter than its surroundings causes eye strain even among readers with healthy vision.
A <picture> element allows selection of sources based on any CSS media query. When images have light backgrounds, I like to include dark variants to complement a dark stylesheet using an HTML media attribute: it selects a dark variant when the user has selected dark mode and is using a screen media type. Requiring the screen media type prevents selection of dark variants when printing. Printer paper is almost always white, so dark images could waste ink. Ink waste is a sensitive issue among many students: school printers sometimes charge students who exceed a given ink quota. Ask me how I know!
Light and dark variants of legacy formats (PNG, JPG, GIF), WebP, and AVIF can cause some of my <picture> imagesets to have up to six image variants. I could fully automate the process using my static site generator (Hugo) if I wanted to. Since I do want to inspect each image and compress to the minimum acceptable quality, I settled for partial automation using shell scripts and a Hugo shortcode.
picture containing a dark variant and two image formats.
<picture>
<source type="image/webp" srcset="/p/light.webp">
<source type="image/webp" srcset="/p/dark.webp"
media="screen and (prefers-color-scheme: dark)">
<source type="image/png" srcset="/p/dark.png"
media="screen and (prefers-color-scheme: dark)">
<img src="/p/light.png" alt="ALTERNATIVE_TEXT."
width="WIDTH" height="HEIGHT">
<picture>
SVG images
I only recommend using SVG in images; avoid using them in embeds, objects, or directly in the body. Remember that users may save images, and open them in a non-browser image viewer with reduced SVG compatibility. To maintain maximum compatibility, stick the subset of the secure static processing mode of SVG Static. Specifically, the subset that appears in the SVG Tiny Portable
This advice might seem daunting, but it’s usually easy to use existing tools to generate an SVG Tiny file and manually edit it to support the SVG secure static mode. SVGs that conform to this subset should be compatible with Qt5’s SVG implementation, librsvg (used by Wikipedia and GNOME), and most operating systems’ icon renderers. Moreover, tools like usvg can simplify complex SVGs to a tiny subset of the SVG spec.
Two tools that can optimize the size of an SVG file are SVGO and the now-discontinued svgcleaner. Too much lossy SVG compression can sometimes reduce the effectiveness of gzip and Brotli compression. Compress in moderation.
Layout
Page layout should be simple, predictable, consistent, familiar, and static. Avoid anything too unusual, since novelty could introduce a learning curve.
Accessible skimming
Keep the source order, DOM order, and visual order identical to ensure consistent behavior when navigating with the mouse, keyboard, assistive-technology, et al. Doing so should also result in a logical Tab order.
Guideline 2.4 Navigable of the WCAG lists multiple criteria related to identifying and skipping sections of your pages, and for good reason:
-
Users of switch access controls find it slow and frustrating to navigate long lists of focusable items.
-
Screen readers make it difficult to consume poorly-organized content non-linearly.
-
Clients that don’t support CSS can’t prioritize content using a supplied stylesheet.
The list goes on: nearly every reader reliant upon assistive technologies (AT) struggles to skim through poorly-organized pages.
Related items need to be semantically grouped together. Group navigation links together in <nav> elements; sections under headings and landmarks; lists under <ol>, <ul>, or <dl>; etc. to give assistive technologies the means to skip over multiple items at once.
The first or second heading in the DOM, and the highest heading level, should be the page title marking the start of your main content (i.e. it should come after the site title, site navigation links, etc). Use elements like <main>, <nav>, and <article> to provide landmarks. If multiple navigation elements exist, give your main navigation element an aria-label or a heading.
Remember that not all landmarks are announced by screen readers; for instance, many screen readers don’t announce the ending of a <header> element in an article. An <hr> element is a good way to force the ending of a landmark to be visible: it introduces a thematic break between sections that is visible to assistive technologies and user-agents that don’t support CSS.
Consider adding a “skip link” if some pages require many Tab keystrokes to reach the main content.note 33 Visually-impaired users generally prefer navigating by headings or landmarks, but screen reader beginners and motor-impaired users still benefit from a skip link. Skip links are especially helpful when pure heading- and landmark-based navigation isn’t optimal.
If your skip link toggles visibility states when focused, ensure that it doesn’t move any existing content; see the “Layout shifts” section for more details. If it appears over existing content, it needs to have a solid background; if you set the background color, set a foreground color too as described in the “About custom colors” section.
Friendly navigation
Users of ATs such as screen readers primarily navigate through landmarks, headings, and paragraphs. Sometimes they also navigate between links. Headings and link names need to be unique and descriptive enough to serve as navigational aids; paragraphs shouldn’t be too long.
Try using a tool to view a list of all your link names. Just about every screen reader and some browser extensions should offer this functionality. Minimize links with ambiguous names, and ensure that identical link names have identical destinations.
Think twice before placing important content immediately after skippable content such as nested landmarks, long code snippets, figures, and large lists. AT users who wish to skip content may jump directly to the next heading, glossing over anything between the skippable content and subsequent heading; this is especially common on mobile devices.note 34 When it makes sense to do so, place skippable content in its own sections and/or at the end of its parent section.
Single-column layout
The remainder of the “Layout” section is possibly the most subjective part of this article, and the part with the most exceptions. Consider it more of a weak suggestion than hard advice. Use your own judgement.
A simple layout looks good at a variety of window sizes, rendering responsive layout changes unnecessary. Textual websites really don’t need more than a single column; readers should be able to scan a page top-to-bottom, side-to-side exactly once to read all its content.
Verify this using the horizontal-line test: mentally draw a horizontal line across your page, and make sure it doesn’t intersect more than one landmark. Ideally it shouldn’t intersect multiple different grouping elements either. The “source order viewer” in Chromium’s DevTools can assist with this process.
Keeping a single-column layout that doesn’t require responsive layout changes ensures smooth window re-sizing. Doing so while keeping an identical source, DOM, and visual order ensures layout consistency: spatial references such as “the paragraph above this heading” or “the bottom image of a section” will be unambiguous to screen reader, phone, and desktop users. It also ensures that selection behavior and caret movements during caret navigation remain predictable. Achieving this type of layout entails using the WCAG 2.2 techniques C27: Making the DOM order match the visual order as well as C6: Positioning content based on structural markup.
Nontrivial use of width-selectors, in CSS queries or imagesets, is actually a powerful vector for JS-free fingerprinting. This is one of the reasons why I didn’t recommend resolution- or dimension-aware imagesets in the image optimization section.
Exceptions exist: one or two very simple responsive changes won’t hurt. The main anti-patterns are adjusting the relative order of elements, layout shifts dramatic enough to cause confusion, and making requests based on media queries that reveal fingerprintable information.
Sidebar pitfalls
Sidebars are probably unnecessary, and can be quite annoying to readers who re-size windows frequently. This is especially true for tiling window manager users like me: we frequently shrink windows to a fraction of their original size. When this happens to a website with a sidebar, one of two things happens:
-
The site’s responsive design kicks in: the sidebar vanishes and its elements move elsewhere. This can be quite CPU-heavy, as the browser has to both re-wrap the text and handle a complex layout change. Frequent window re-sizers will experience lag and battery loss, and might need a moment to figure out where everything went.
-
The site doesn’t use responsive design. The navbar and main content are now squeezed together. Readers will probably close the page.
Neither situation looks great.
Low Vision User Accessibility Requirements by the WAI is a work-in-progress document that describes issues caused by significant responsive changes. It encourages designers to “maintain point of regard” during responsive changes (the “point of regard” is the place a reader is looking at). Unfortunately, it’s not always possible to “guess” whether the point of regard is the main content or a sidebar.
Sidebar alternatives
Common items in sidebars include tag clouds, an author bio, and an index of entries; these aren’t useful while reading an article. Consider putting them in the article footer or—even better—dedicated pages. This does mean that readers will have to navigate to a different page to see that content, but they probably prefer things that way; almost nobody who clicked on “An opinionated list of best practices for textual websites” did so because they wanted to read my bio.
Don’t boost engagement by giving readers information they didn’t ask for; earn engagement with good content, and let readers navigate to your other pages after they’ve decided they want to read more.
Line length
As words-per-line decrease (by increasing zoom or narrowing the viewport), line lengths grow more varied. Justifying text will cause uncomfortable amounts of whitespace. In fact, Text is not justified
is explicitly mentioned in the WCAG Success Criterion 1.4.8.
The WCAG recommends a max line length of 80 characters (40 characters for CJK languages) as a AAA success criterion (SC 1.4.8). However, studies seem to have mixed results; some people find it easier to read lines around 90 characters long, while others struggle beyond the 50-character mark.
I think the WCAG over-simplified a complex issue to make this success criterion easier to understand. The guideline in its current form encourages wrapping lines at uneven lengths, since proportional text can take up varying amounts of space for a given character count. It would be better to specify an average character length, allowing lines with narrow characters (e.g. “I”, “l”) to exceed it. Then again, the AAA level was never intended to be a blanket requirement.
Some of my links display long link-text; short line lengths can break these link texts too much, which can slightly hurt readability. Of course, narrow viewports will obviously make short line lengths non-negotiable. I decided to give article bodies a width of 36em, which corresponds to just over 80 characters on most default stylesheets. I opted to use em instead of ch for consistency and for better compatibility with some uncommon browsers (NetSurf, Dillo, old versions of mainstream browsers, and others).
I also ensured that my site supports CSS overrides, window-resizing, zoom levels past 200%, and most “reading mode” implementations. This should help accommodate a wide range of line-length preferences while still looking accessible enough by default.
When setting max line lengths, use a CSS media query to ensure that printed versions of a page use the full page width. This should save some paper.
screen media type:
@media screen {
html {
max-width: 45em;
padding: 0 3%;
}
div[itemprop='articleBody'] {
margin: auto;
max-width: 36em;
}
}
Small viewports
People read on a variety of viewport sizes. Page structure must be simple enough to handle these layouts smoothly.
Narrow viewports are popular
Not every phone has a giant screen: millions of people around the world use Web-enabled feature phones. The Jio Phone 2, for instance, is narrow enough to fall through a belt loop: it sports a screen that’s just over 3.6 cm (1.44 inches) wide. Furthermore, some programs sport browser windows in sidebars (c.f. Mozilla’s side view, Vivaldi Web Panels). Users who leverage floating or tiling windows rather than maximizing everything could use viewports of arbitrary dimensions.
Nowadays, even tiny smartwatches have built-in browsers; users who navigate to links in smartwatch message and email apps will use simplified browsers that fit on their wrists. Apple published a video about WebKit on WatchOS (here’s a text summary of the video, starting at the “New types of devices” section). The Apple Watch Series 6 has a viewport that’s 162 CSS pixels wide; it emulates an iPhone’s viewport and shows a zoomed-out version of the page unless the page includes a “device-adjust” meta tag, the same way phones emulate desktop viewports without a “viewport” meta tag. Samsung Internet is a popular option for Wear OS users, whose viewports are often just 150 CSS pixels.
Wide items
A single element wider than the viewport will trigger horizontal scrolling for the entire page. This is especially problematic for long pages that already require excessive vertical scrolling.
Long words, especially in headings, can trigger horizontal overflow. Test in a viewport that’s under 240 pixels wide (DPR=1) and observe any words that trail off of the edge of the screen. Add soft hyphens to these words using the ­ entity.
Most modern browsers support the hyphens CSS 3 property, but full automatic hyphenation is usually an overkill solution with a naive implementation. Automatic hyphenation will insert hyphens wherever it can, not necessarily between the best syllables. At the time of writing, humans are still better at hyphenating than most software implementations. I only enable full hyphenation on the narrowest of viewports.
Users employing machine translation will not benefit from your soft hyphens, so don’t expect them to always work as intended. Translation tools might also replace short words with long ones. Soft hyphens and automatic hyphenation are both flawed solutions, but I find soft hyphens to be less problematic.
Where long inline <code> elements can trigger horizontal scrolling, consider a scrollable <pre> element instead. Making a single element horizontally scrollable is far better than making the entire page scrollable in two dimensions. Hard-wrap code blocks so that they won’t horizontally scroll in most widescreen desktop browsers.
Be sure to test your hyphens with NVDA or Windows Narrator: these screen readers’ pronunciation of words can be disrupted by poorly-placed hyphens. Balancing the need to adapt to narrow screens against the need to sound correctly to a screen reader is a complex matter.note 35 The best place to insert a hyphen is between compound words. For example, splitting “Firefighter” into “Fire-fighter” is quite safe. Beyond that, try listening to hyphenated words in NVDA to ensure they remain clear.
Keeping text together
Soft hyphens are great for splitting up text, but some text should stay together. The phrase “10 cm”, for instance, would flow poorly if “10” and “cm” appeared on separate lines. Splitting text becomes especially painful on narrow viewports. A non-breaking space keeps the surrounding text from being re-flowed. Use the HTML entity instead of a space: 10 cm. Practical Typography by , describes where to use the non-breaking space in more detail.
One exception to the rules from Practical Typography: don’t use a non-breaking space if it would trigger two-dimensional scrolling on a narrow viewport. Between broken text and two-dimensional scrolling, broken text is the lesser evil. I personally set a cutoff at 2.5 cm (1 inch) at 125% zoom.
Pictures of text
You should only use pictures of text when the visual presentation of the text is part of the information you’re trying to convey. Always be sure to test how such an image looks on a narrow screen.
Images do not reflow their text. When the viewport is narrower than the image dimensions, you can instruct the browser to do one of three things:
- Allow the image to exceed the viewport width, triggering two-dimensional scrolling for the whole page.
- Shrink the image to fit the viewport, causing the text in the image to shrink with it.
- Allow the image to horizontally overflow.
I already covered the first option in the prior subsection. If you expect viewers to read the text in the image and you don’t link an image transcript, the second option isn’t ideal. Overflow is almost never what we want.
The best compromise is to ensure that the image isn’t too wide, and can support large text on a narrow viewport. Lines of text in images should contain as few characters as possible. For a good example, see the “In defense of link underlines” section.
If the text needs to be readable, check its APCA levels. At large sizes, the contrast shouldn’t be too high; at small sizes, it shouldn’t be too low.
Indented elements
Most browser default stylesheets were not optimized for narrow viewports, so narrow-viewport optimization is one of few good reasons to override the defaults. The best example of widescreen bias in browser stylesheets is indentation.
The HTML standard’s section 4.4.4 covers blockquotes. It recommends placing a <blockquote> element inside a <figure> and citations in a <figcaption> to show a semantic relationship between a quotation and its citation.
Browser default stylesheets typically give <figure> elements extra margins on either side. <blockquote> elements have a large indent. Combining these two properties gives the final quotation an excessive visual indent, wasting precious vertical screen space. When quoted text contains list elements (<ol>, <dl>, <ul>), the indentation alone may fill most of a narrow viewport!
I chose to remove the margins in <figure> elements for quotations and code snippets. If you’re reading this page with its own stylesheet enabled, in a CSS 2 compliant browser, you might have noticed the blockquotes on it have a minimal indent and a thick border on the left rather than a full indent. These two adjustments allow blockquotes containing bulleted lists to fit on most narrow viewports, even when wrapped by a <figure> element.
Indented elements can be difficult to distinguish when nested. A <blockquote> may not be visible if it contains an <ol> or <ul>. My left-border approach resolves this ambiguity.
Another example: outside the Web, I prefer indenting code with tabs instead of spaces. Tab widths are user-configurable, while spaces aren’t. HTML pre-formatted code blocks, however, are best indented with two spaces. Default browser stylesheets typically represent tabs with an excessive indent, which can be annoying on narrow viewports.
Short viewports
Designers often use figures to “break up” their content, and provide negative space. This is good advice, but I don’t think people pay enough attention to the flipside: splitting up content with too many figures can make reading extremely painful on a short viewport. Design maxims usually lack nuance.
Small phones typically support display rotation. When phones switch to landscape-mode, vertical space becomes precious. Fixed elements (e.g. dickbars) become a major usability hazard. Ironically, the WCAG’s own interactive Techniques reference is a perfect example of how fixed elements impact usability on short screens.

When filtering criteria on the Quickref Reference page, a dickbar lists active filters. I increased the zoom level; you may have to add more filters to fill the screen with a smaller font.
Keeping the most important content above the fold (the part of the page that’s visible without scrolling) is hard on small screens. Nonetheless, it’s an important element of cognitive accessibility. Users may struggle to identify a page or navigate a site if the title and navigation links are below the fold. The WAI’s mobile accessibility guidelines share this recommendation.
Make important tasks and features on the site stand out and easy to find.
This includes:
- […]
- Placing the tasks/features towards the top of the page so the user does not have to scroll to see them.
- Placing the tasks/features toward the top of the content so assistive technology finds them quickly.
- […]
- Including key tasks at a top level of the main navigation.
Spacing
The previous “small viewports” section may tempt you to make your content as dense as possible. Please don’t overdo it.
There’s an ideal range somewhere between “cramped” and “spaced-apart” content. Finding this range is difficult. The best way to resolve such difficult and subjective issues is to ask your readers for feedback, giving disproportionate weight to readers with under-represented needs (especially disabled readers).
Non-interactive space
Excessive indentation makes reading difficult on narrow viewports, but preserving some indentation is still useful.
For now, I’ve decided to keep some indentation on list elements (<ol>, <dl>, <ul>) since I often fill them with links (see this article’s table of contents for an example). This indentation provides important non-interactive negative space.
Readers with hand tremors depend on this space to scroll without accidentally selecting an interactive element; Axess Lab described the issue in Hand Tremors and the giant button problem. Readers who double-tap to jump or zoom can’t do so if there’s no screen region that’s “safe to tap”. Having clearly distinguished links also helps users decide safe places to tap the screen; see the section on link underlines for more information.

I made sure to leave enough non-interactive space in my homepage’s webring list to accommodate a 48 px tap target, with extra space in between.
Always make sure one non-interactive region exists on the screen at a time, 48 CSS pixels in either dimension; that’s the size of a tap target.
Tap targets
Tap targets should be at least 44 pixels tall and wide according to the WCAG; this is large enough to easily tap on a touchscreen. The WCAG makes an exception for inline targets, like links in a paragraph.
Google has more aggressive tap-target recommendations: it recommends raising the limit 48 px with with 8 px gaps, going so far as to make tap target size a ranking factor in search.
The edges of a touch screen are often tap-targets (the top edge might toggle navigation or scroll to the top, the bottom may have home/back buttons, and the right side may have a scrollbar), so keep elements slightly away from those. Keeping away from edges is doubly important on phones: they may have rounded edges that are easy to miss-tap, or reinforced cases that make the very edge of a screen difficult to reach.
On lists with many links, I had to find other ways to ensure adequate tap-target size and provide sufficient non-interactive space for readers with hand-tremors to scroll. Some examples:
-
The webmention list after this article separates links with timestamps and some paragraph spacing.
-
Some list items have links with extra padding. These include description terms (
<dt>) and navigation elements, such as the table of contents or the site header and footer, -
The posts list and the list of related articles at the beginning of one of my posts separates links with non-interactive text descriptions
-
This list separates two list-items containing links with a third list-item that lacks links.
Line spacing
Increasing the line-spacing a bit will make tap targets larger and improve comprehension by readers with cognitive disabilities. A WCAG AAA Success Criterion is to allow 1.5 space units between lines; the WAI’s Cognitive and Learning Disabilities Accessibility Task Force recommends changing this Success Criterion’s level, finding it too important to be relegated to AAA status.
Line spacing (leading) is at least space-and-a-half within paragraphs, and paragraph spacing is at least 1.5 times larger than the line spacing.
Non-
Fully standards-compliant browsers aren’t the only programs people use. They also use “reading mode” tools and services.
Reading modes leverage article extractors such as Readability (integrated into Firefox, Epiphany, Brave, Vivaldi, and others), DOM Distiller (integrated into Chromium), Brave SpeedReader, and Trafilatura (powers a variety of tools and services). A host of other proprietary options exist: Diffbot powers services like Instapaper, Mozilla’s Pocket has its own secret parsers, and countless “send to e-reader” services have amassed loyal users. Safari’s proprietary fork of Readability has grown quite complex compared to upstream; Edge’s Immersive Reader is a mystery to me, with a problematic stylesheet.
I don’t recommend catering to each tool’s non-standard quirks. Studying their design reveals that they observe open standards, to varying degrees. Readability, DOM Distiller, and Trafilatura understand plain-old, semantic HTML (POSH).
POSH should be enough for most use-cases, but some authors want to go further. For example, they may want a byline or published date to show up in these modes.
Most extractors fetch these values using open standards for structured data. The most well-supported option is microformats (Readability is one of the few that supports the newer microformats2). Some support schema.org vocabularies in microdata or JSON-LD syntaxes, or Dublin Core vocabularies in RDFa. Most parse <meta> tags from the document <head>, but others don’t due to misuse and overly aggressive SEO.
Sorry, that was a lot of jargon for a single paragraph. Unfortunately, describing those terms is out of scope for this post. If you’d like to dive down this rabbit hole, read about the “Semantic Web”.
Some reading-mode implementations also support DPUB-ARIA, but I’d caution against using ARIA when POSH is sufficient: “bad ARIA” can be far more harmful to screen readers than “no ARIA”. Only use ARIA to fill in gaps left by POSH.
Again: avoid catering to non-standard implementations’ quirks, especially undocumented proprietary ones. Let’s not repeat the history of the browser wars. Remember that some implementations have bugs; consider reporting issues when one arises. More information about standard and non-standard behavior of reading modes is in the article Web Reading Mode: The non-standard rendering mode by .
Reading modes aren’t the only non-browser user agents out there. Plain-text feed readers and link previewers are some other options. I singled out reading modes because of their widespread adoption and value. Decide which other kinds of agents are important to you (if any), and see if they expose a hole in your semantics.
Machine translation
Believe it or not, the entire world doesn’t speak your website’s languages. Browsers like Chromium, Microsoft Edge, and Safari have integrated machine translation to translate entire pages. Users can also leverage online website translators such as Google Translate or Bing. These “webpage translators” are far more complex than their plain-text predecessors.
Almost every word on your site can be re-written. Prepare for headings to change length, paragraphs to grow and shrink, or hyphenation to disappear. Your site’s layout should make sense even when the length of each textual element is changed.
Machines can’t reliably translate images of text, since OCR is error-prone. See the image transcripts section for remedies.
Incorrect spelling and poor grammar in an original work can reduce the accuracy of a machine-translated derivative. Be sure to proofread.
POSH helps translation engines
To ensure that pages get machine-translated properly, make proper use of semantic HTML. Daniel wrote about this topic too in Semantic markup improves the quality of machine-translated texts; I highly encourage giving his article a read.
Elements to pay close attention to include <code>, <samp>, <var>, <kbd>, <abbr>, and <address>. The semantic information conveyed by these elements supplies important context to translation algorithms.
Only after POSH is insufficient should you attempt to “override” behavior with the translate HTML attribute. Setting translate="no" or translate="yes" should override the behavior of standards-compliant translation engines. If you’re unsure whether or not to use a translate attribute, search the relevant word or phrase on Keybot to see how human translators approached it.
For example: machine translation will leave <code> and <samp> blocks as-is. Perhaps you could annotate comments within code with a translate="yes" attribute. However, translation engines should leave variables within those comments as-is.
Google’s style guide recommends annotating format placeholders in code blocks with the <var> element; consider doing so and adding a translate="yes" attribute to placeholder values, at your discretion. For an example, check this article’s code sample describing my PNG optimization pipeline. Most implementations do not yet support translate="yes" embedded inside untranslated blocks, but I’m counting on this changing.
Changing text direction
Consider the implications of translating between left-to-right (LTR) and right-to-left (RTL) languages. Do a search through your stylesheets for keywords like “left” and “right” to ensure that styles don’t depend too heavily on text direction. Once you’ve cleared the low-hanging fruit, try translating the page to a language like Arabic.
Websites following this page’s layout advice shouldn’t need much adjustment. RTL Styling 101 is a comprehensive guide to what can go wrong and how to fix issues.
Current limitations
Machine translation is always improving. Today, it has some limitations which I expect will be resolved with time.
translate="yes" attributes nested inside un-translated blocks (code snippets, blocks with translate="no", etc.) are not yet supported by most translation tools. It’s a relatively new attribute, so flaky support is understandable.
Machine translators often skip aria-label and aria-description. For this reason, authors prefer using aria-labelledby and aria-describedby instead.
Microsoft Edge is the only browser I know of to adjust text-direction during translation, but it breaks when faced with inline <code> and <span> elements.
Inaccessible default stylesheets
Simple sites should err on the side of respecting default stylesheets. With rare exceptions, there are only two times I feel comfortable overriding default stylesheets:
- Gently adjusting a parameter rather than completely changing an element’s appearance. Typically, this involves adjusting dimensions.
- Fundamentally altering an element’s appearance. I only feel comfortable doing this when the defaults are truly inaccessible, or clash with another accessibility enhancement I made.
My previous advice regarding line spacing and maximum line length fell in the first category. My approach to re-styling <blockquote> elements, adding borders, and using sans-serif fell in the latter category.
This section contains miscellaneous advice regarding the latter category of stylesheet overrides.
Monospace handling
By default, most browsers render monospace text at a reduced size. If you want your monospace text to be readable, set its font family to monospace, monospace (sic).
Font family alone is not enough to distinguish an element from its surroundings. For <pre>, <code>, and <samp> elements, I recommend supplementing the font family change with a soft border. As described in the “Color overrides and accessibility” section, borders are preferable to background colors because they don’t override the user-agent’s preferred foreground and background colors.
Finally, it’s important to distinguish <kbd> from <code>, <samp>, and regular body text.
<code> and <samp>, <pre>, and <kbd> from each other and from body text.
code, kbd, samp {
font-family: monospace, monospace;
}
pre,
:not(pre) > code, :not(pre) > samp {
border: 1px solid;
}
/* Dark borders in text are harsh */
:not(pre) > code, :not(pre) > samp {
border-color: #999;
}
kbd {
font-weight: bold;
}
Focus indicators
The default focus indicators are hard to see in certain browsers (e.g. Firefox and WebKit), especially when the focused element already has a border. We can override them to make them more accessible.
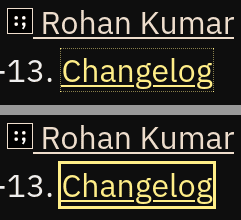
Firefox 99’s default focus indicator, before and after my adjustments.
On one hand, users who need enhanced focus visibility may override the default focus indicators in their browser preferences; I’d like to support such overrides. On the other hand, relying on these customizations would violate the “accessible by default” directive. This would exclude Tor Browser and fingerprinting-averse readers, as well as anybody who has to borrow a machine or browser they don’t own or haven’t customized yet. This is another one of the few areas where I’d recommend overriding browser default stylesheets.
The WCAG Success Criterion 2.4.12 recommends making focus indicators 2 px thick. While this success criterion is only AAA-level, it’s easy enough to meet and beneficial enough to others that we should all meet it.
You can use :focus and :focus-visible to highlight selected and keyboard-focused elements, respectively. Take care to only alter styling, not behavior: only keyboard-focusable elements should receive outlines. Modern browser stylesheets use :focus-visible instead of :focus; old browsers only support :focus and re-style a subset of focusable elements. Your stylesheets should do the same, to match browser behavior.note 36
:focus when :focus-visible works, to match existing behavior. I also override :focus styling only on the subset of focusable elements that would normally show an outline. Based on the post :focus-visible and backwards compatibility by .
a:focus,
[tabindex]:focus {
outline: 3px solid;
}
@supports selector(:focus-visible) {
a:focus:not(:focus-visible),
[tabindex]:focus:not(:focus-visible) {
outline: none;
}
}
:focus-visible {
outline: 3px solid;
}
Update: Firefox 104 has adopted a much better 2-color focus indicator; supplying a custom indicator will be less important in 2023 once a Firefox ESR version above 104 becomes available.
Screen reader improvements
This section focuses on ways to improve screen reader support that have not already been covered. The most important measures (semantic HTML, good alt-text and image context, correct spelling, etc.) have already been covered in previous sections.
Try reading your screen through a drinking straw for an hour to get an idea of the limited context that a blind user has. You simply cannot scan the entire page at a glance with a screenreader - you have to listen to the structure of it carefully and remember all that, or read through the entire thing to find stuff, unless there are explicit associations such as longdesc.
Split elements and possessive hyperlinks
Some screen readers split up sections by HTML elements. This means HTML elements in the middle of a sentence will trigger pauses. The problem comes up frequently on sites that use excessive inline formatting.
This is especially concerning on my website, where I tend to hyperlink peoples’ names (a common practice on the IndieWeb): making names possessive with an “apostrophe + s” creates pronunciation issues. “Seirdy’s Home” could be read as “Seirdy. Link. S. Home” if the word “Seirdy” is a hyperlink.
A workaround is to use the “text” ARIA role to remove the semantics of elements. This workaround doesn’t work in certain screen readers, including Orca, so don’t count on it.
role="text" to prevent splitting in a multi-line heading. By
, Text Splitting Causes Screen Reader Problems
<h1>
<span role="text">Digital accessibility, <br>
for everyone.
</span>
</h1>
If you’re unfamiliar with ARIA, always remember the First Rule of ARIA: No ARIA is better than Bad ARIA. ARIA exposes a host of accessibility hazards when used improperly, so only use this approach when there’s no good alternative. Furthermore, role="text" isn’t actually standard ARIA; its proposed inclusion into the ARIA specification was controversial. See issue 870 of WAI-ARIA for some problems with it.
The best solution for possessive nouns is to include the “apostrophe + s” inside the hyperlink.
Other tips for screen readers
Designers already test their websites with multiple browser engines to ensure cross-browser compatibility. Screen readers deserve the same treatment. Orca, VoiceOver, NVDA, Narrator, JAWS, TalkBack, ChromeVox, KaiOS Readout, et al. all have unique behavior. In addition, different browsers—even different Chromium forks—expose content to screen readers differently. You’ll need to test multiple screen readers in multiple browsers, and keep track of updates to both. See why standards compliance is important?
Screen readers on touch screen devices are also quite different from their desktop counterparts, and typically feature fewer capabilities. Be sure to test on both desktop and mobile.
Screen reader implementations often skip punctuation marks like the exclamation point (!). Ensure that meaning doesn’t rely too heavily on such punctuation.
Screen readers have varying levels of verbosity. The default verbosity level doesn’t always convey inline emphasis, such as <em>, <code>, or <strong>. Ensure that your meaning carries through without these semantics.note 37
Default verbosity does, however, convey symbols and emoji. Use symbols and emoji judiciously, since they can get pretty noisy if you aren’t careful. Use aria-labelledby on symbols when appropriate; I used labels to mark my footnote backlinks, which would otherwise be read as right arrow curving left. If you have to use a symbol or emoji, first test how assistive technologies announce it; the emoji name may not communicate what you expect.
Beware of display and visibility CSS properties; they can interfere with content reported to screen readers (see quote from Steve Faulkner). Whenever you use one of those properties, re-test with screen readers just to be safe.
Sometimes [using
displayproperties] can have an unintended effect of nuking the semantics of the elements, as conveyed to screen reading software, in the browser accessibility tree. Screen readers and other assistive tech, in general, do not have direct access to the HTML DOM, they are provided access to a subset of information in the HTML DOM via Accessibility APIs. Sometimes what an element represents in the HTML DOM is not how it is represented in the accessibility tree.If what is represented in the accessibility tree does not represent the developer’s intended UI, it’s either (wittingly / unwittingly) the fault of the developer or the browser. But what we can be sure of, in these cases, is that it is not the fault of the screen reader.
Future users
The number of people using your site in the future is hopefully greater than the number of people using your site in the present. Accordingly, your pages need to work correctly in the future.
Much of this section borrows from the article This Page is Designed to Last; I highly recommend giving it a read.
Third parties
I’ve already made a privacy and performance case against third-party resources in an earlier “Third-party content” subsection. Another reason to avoid third-party resources is longevity. Third-party scripts, styles, frames, and images all depend on someone else’s host keeping the resource available at the same URL; over time, these tend to disappear. Sticking to first-party content reduces these points of failure.
Third-party content is especially problematic when it’s hosted on modest hardware. If your site “goes viral”, your traffic could take down the third-party site or prompt them to disable hotlinking. Serve assets yourself.
Dead links
On the same note: your internal and external links to other pages need to change with time. Use a broken-link checker regularly to ensure that your content stays alive. I recommend checkers like lychee and htmltest because they can cache results. My site has a bit under two thousand links at the time of writing; checking all of them at once would be exhausting, but using a week-long cache allows me to split this over seven days.
Whenever you link to a page, try to archive a snapshot of it. The Wayback Machine, archive.today, and Ghostarchive are popular options. Archival is one of the few times I recommend using a third-party service; a service like the Wayback Machine will likely outlive your website. That being said, self-hosted solutions like ArchiveBox do exist.
If you link often enough, archival might be something worth automating. The Wayback Machine offers an API, and allows registered users to mass-archive archive all outlinks in a page.
Reproducibility
Imagine your typical “modern” website’s deployment pipeline. It requires thousands of dependencies to build. It uses bespoke tools to deploy to a service provider with a custom non-standard stack (e.g. Fly.io, Heroku, Cloudflare Workers, AWS Lambda).
Ten years from now, how much of this will still work?
Try to ensure that your website can be archived, and/or easily re-built and served on an ordinary server. This way, your work can still be made accessible after you’re gone. For example: all my site requires to build is a tarball of statically-linked binaries, a POSIX shell, and a decent Make implementation (bmake and GNU make work) to build; see my build manifest. To serve, it just needs a static web server.
Testing
If your site is simple enough, it should automatically handle the vast majority of edge-cases. Different devices and browsers all have their quirks, but they generally have one thing in common: they understand POSH.
No matter how simple a page is, I don’t think simplicity eliminates the need for testing. I outlined the need to analyze actual run-time behavior in another post exploring how code alone doesn’t give the full picture.
Automated tests
Automated tests—especially accessibility tests—are a supplement to manual tests, not a replacement for them. Think of them as time-savers that bring up issues for further research, containing both false positives and false negatives.
These are the tools I use regularly. I’ve deliberately excluded tools that would be redundant.note 38
- Nu HTML checker
- The W3C’s official HTML validator. Valid HTML ensures broader compatibility with a wider range of agents. Note that it uses Jigsaw under the hood for CSS validation, which hasn’t implemented support for certain CSS features I’ve recommended elsewhere on this page. Watch out for false positives.
- axe-core
- The current standard in accessibility testing. Most website auditors that run accessibility checks use this library under the hood.
- Lighthouse
- An auditing tool by Google that uses the DevTools protocol in any Chromium-based browser. Skip the “Accessibility” category, since it just runs a subset of axe-core’s audits. The most useful audit is the tap target size check in its “SEO” category. It’s also convenient for measuring performance with CPU throttling, to simulate low-end mobile devices. Note that your
sandboxCSP directive will need to includeallow-scriptsfor it to function. - Webhint
- Similar to Lighthouse. Again, you can ignore the accessibility audits if you already use axe-core. I personally disagree with some of its hints: the “unneeded HTTP headers” hint ignores the fact that the CSP can have an effect on non-hypertext assets, the “HTTP cache” hint has an unreasonable bias against caching HTML, and the “Correct
Content-Typeheader” recommends charset attributes a bit too aggressively.note 39 - IBM Equal Access Accessibility Checker
- Has a scope similar to axe-core. Its “Sensory Characteristics” audit seems unique.
- AInspector
- A Firefox addon that displays audits in the sidebar. In my experience, it does have many false-positives (especially regarding DPUB-ARIA; see issue 3 for the OpenA11y Evaluation Library); however, it has caught a few issues missed by all other tools.
- Firefox’s Accessibility Inspector
- Supports some very basic audits for contrast, keyboard access, and text labels. The accessibility tree is also a useful way to ensure that elements have accessible names. The keyboard audits have false-positives on non-interactive elements with scrollable overflow, which need to be focusable.
- Chromium’s CSS Overview
- Can show some basic accessibility violations, including contrast violations. I recommend enabling the APCA-based contrast algorithm in the DevTools experimental settings first. Note that this uses an earlier version of APCA and does not account for contrast that is too high.
- testssl.sh (cli)
- SSL Labs’ SSL Server Test (web, proprietary)
- Basically equivalent tools for auditing your TLS setup. I prefer testssl.sh.
- Webbkoll
- Basic security checks, focusing on HTTP headers. I consider it a spiritual successor to Mozilla’s HTTP Observatory.
- Check Your Website
- Slower, more in-depth website checks with an emphasis on security. It covers name server configurations, DNSSEC, DANE, email DNS records, MTA-STS, well-known paths, redirects, certificate transparency, subresource integrity, caching, and well-known ports.
- Internet.nl
- Possibly the harshest website security and modernity check on this list, and my personal favorite. Checks for IPv6 reachability, modern cipher suites and key-exchange params, DNSSEC, and RPKI. It also has handy tools to check an email server, and your own personal connection.
Unorthodox tests
In addition to standard testing, I recommend testing with unorthodox setups that are unlikely to be found in the wild. If a website doesn’t work well in one of these tests, there’s a good chance that it uses an advanced Web feature that can serve as a point of failure in other cases. Simple sites should be able to look good in a variety of situations out of the box.
Your page should easily pass the harshest of tests without any extra effort if its HTML meets basic standards for well-written code (overlooking bad formatting and a lack of comments). Even if you use a complex static site generator, the final HTML should be simple, readable, and semantic.
These tests begin reasonably, but gradually grow absurd. Once again, use your judgement.
-
Test in all three major browser engines: Blink, Gecko, and WebKit.
-
Evaluate the heaviness and complexity of your scripts (if any) by testing with your browser’s JIT compilation disabled.note 40
-
Test using the Tor Browser’s safest security level enabled (disables JS and other features).
-
Load just the HTML. No CSS, no images, etc. Try loading without inline CSS as well for good measure.
-
Print some pages in black-and-white, preferably with a simple laser printer.
-
Test with assistive technologies such as screen readers, magnifiers, and switch controls.
-
Ensure the page responds correctly to browser zoom. No sizes or dimensions should remain “fixed” across zoom levels.
-
Test keyboard navigability with the Tab key and caret navigation. Even without specifying tab indexes, tab selection should follow a logical order if you keep the layout simple.
-
Test in textual browsers: lynx, links, w3m, ELinks, edbrowse, EWW, Netrik, etc.
-
Test in an online website translator tool.
-
Test your feeds (RSS, Atom, JSON, etc.) in multiple readers to ensure they render your markup correctly. Microsoft Outlook uses Word’s Internet-Explorer-based HTML engine to display these contents; Newsboat uses its own custom HTML renderer. Most don’t support CSS.
-
Read the (prettified and indented) HTML source itself and parse it with your brain. See if anything seems illogical or unnecessary. Imagine giving someone a printout of your page’s
<body>along with a whiteboard. If they have a basic knowledge of HTML tags, would they be able to draw something resembling your website? -
Test with unorthodox graphical browser engines, like NetSurf, Dillo, Servo, or the Serenity OS browser.
-
Test how your page renders in ancient browsers, like Netscape Navigator or Tkhtml. Use a TLS terminator or serve over HTTP from localhost.
-
Try printing out your page in black-and-white from an unorthodox graphical browser.
-
Download your webpage and test how multiple word processors render and generate PDFs from it.note 41
-
Combine conversion tools. Combine an HTML-
to- EPUB converter and an EPUB- to- PDF converter, or stack multiple article-extraction utilities. Be creative and enjoy breaking your site. When something breaks, examine the breakage and see if it’s caused by an issue in your markup, or a CSS feature with an equivalent alternative. -
Build a time machine. Travel decades—or perhaps centuries—into the future. Keep going forward until the WWW is breathing its last breath. Test your site on future browsers. Figuring out how to transfer your files onto their computers might take some time, but you have a time machine so that shouldn’t be too hard. When you finish, go back in time to meet Benjamin Franklin.
I’m still on step 17, trying to find new ways to break this page. If you come up with a new test, please share it.
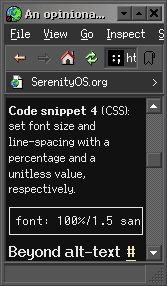
This page in the SerenityOS web browser. TLS 1.2 support isn’t finished yet; I loaded it from a mirror with a compatible cipher suite.
Future updates
This article is, and will probably always be, an ongoing work-in-progress. Some areas I have yet to cover:
-
How purely-cosmetic animations harm readers with learning and cognitive disabilities (e.g. attention disorders).
-
How exposing new content on hover is inaccessible to users with magnifiers, hand tremors, switch access, and touchscreens.
-
Notes on improving support for braille displays.
-
How to work well with caret-based navigation.
-
How to choose phrasings such that some meaning can be inferred without understanding numbers, for dyscalculic readers. This is more applicable to posts whose main focus is not mathematical or quantitative.
-
How to include mathematical notation in a way that maximizes compatibility and accessibility.
-
Keypad-based navigation on feature phones (c.f. KaiOS devices).
-
How keyboard navigation can be altered by assistive tools such as screen readers.
-
How to avoid relying too much on formatting, for user agents that display unformatted text (e.g. textual feed readers like Newsboat)
-
Elaboration on how authors should delegate much of their formatting to the user agent, and how CSS resets are a symptom of a failure to do so.
-
Keyboard-driven browsers and extensions. Qutebrowser, Luakit, visurf, Tridactyl, etc.
-
Ways to support non-mainstream and older browsers by supporting subsets of specifications and using progressive enhancement.
-
Avoiding
_blanktargets in URLs unless absolutely necessary. -
Ways to improve comprehension by readers who struggle to understand non-literal language (certain cognitive disabilities, non-native speakers unfamiliar with idioms, etc.). I might wait until the WAI-Adapt: Help and Support Module draft specification matures and its vocabularies gain adoption before going in depth.
-
Spatial navigation
-
Other accessible writing tips, maybe after I get a copy of Writing Is Designing by and . A relevant excerpt on writing accessibly is on A List Apart.
-
Rules for descriptive link text, for screen reader navigation and for user-agents that display links as footnotes (e.g. some textual browsers with the
dumpflag).
Conclusion
There are so many ways to read a page; authors typically cater only to the mainstream ones. Some ways to read a page I covered include:
- Screen readers
- Switch access
- Navigating with the Tab key
- Caret navigation
- Navigating with hand-tremors
- Content extractors or “Reader Mode”
- Low-bandwidth connections
- Unreliable, lossy connections
- Metered connections
- Hostile networks
- Using in-page search
- Downloading offline copies
- Extra-narrow viewports
- Mobile devices in landscape mode
- Frequent viewport-resizers
- Printouts with rationed paper or ink
- Textual browsers
- Disabling JavaScript
- The Tor Browser’s “Safest” mode
- Non-mainstream browser engines
- Browsing without CSS
- Altering, injecting, or replacing CSS
- Non-default color palettes
- Forced color palettes
- Adblockers, with various filter-lists
- Blocking third-parties
- Disabling frames, images, and cookies
- User-selected custom fonts
- Machine translators
Each of these may be dismissed as a “niche”, especially given a profit motive (or worse, a growth imperative). Yet many niches add up to a large population. Every person who grows old becomes disabled; every long-distance traveller experiences poor connections.
Moreover, I don’t think that the size of a disadvantaged population should always matter. I understand weighing population size if you have to make a trade-off between two conflicting special needs, but I don’t think the aesthetic preferences of the majority are more important than supporting a disadvantaged minority.
Before you throw up your hands and decide you can’t help everyone, take another skim through this page. Notice how much repetition exists between sections. Nearly every bullet-point I listed benefits tremendously from plain-old, semantic HTML (POSH). If your page is usable with nothing but POSH, you’ve done half the work already.
Acknowledgements and further reading
Initial versions of this page were inspired by existing advocates for web minimalism.
Parts of this page can be thought of as an extension to David Copeland’s principles of Brutalist Web Design.
Raw content true to its construction:
Content is readable on all reasonable screens and devices.
Only hyperlinks and buttons respond to clicks.
Hyperlinks are underlined and buttons look like buttons.
The back button works as expected.
View content by scrolling.
Decoration when needed and no unrelated content.
Performance is a feature.
The 250kb club gathers websites at or under 250kb, and also rewards websites that have a high ratio of content size to total size.
The 10KB Club did the same with a 10kb homepage budget (excluding favicons and webmanifest icons). It also had guidelines for noteworthiness, to avoid low-hanging fruit like mostly-blank pages.
My favorite website club has to be the XHTML Club by , the creator of the original 1mb.club.
Also see Motherfucking Website. Motherfucking Website inspired several unofficial sequels that tried to gently improve upon it. My favorite is Best Motherfucking Website.
The Web Bloat Score calculator is a JavaScript app that compares a page’s size with the size of a PNG screenshot of the full page content, encouraging site owners to minimize the ratio of the two.
One resource I found useful (that eventually featured this article!) was the “Your page content” section of Your Personal Website by .
If you’ve got some time on your hands, I highly recommend reading the Web Content Accessibility Guidelines (WCAG) 2.2. The WCAG 2 standard is technology-neutral, so it doesn’t contain Web-specific advice. For that, check the How to Meet WCAG (Quick Reference). It combines the WCAG with its supplementary list of techniques.
The WCAG are an excellent starting point for learning about accessibility, but make for a poor stopping point. Much of the content on this page simply isn’t covered by the WCAG. One of my favorite resources for learning about what the WCAG doesn’t cover is Axess Lab’s articles.
I’ve learned about a great number of underrepresented ways to browse from the Fediverse, particularly from this subthread asking people to share (requires JavaScript; plaintext mirror). Several responses informed updates to this page.
An early version of this article received useful responses when I posted it to Lobsters; I incorporated some feedback shortly afterward.
A special thanks goes out to GothAlice for the questions she answered in #webdev on Libera.Chat.
Notes
-
Many addons function by injecting content into pages; this significantly weakens many aspects of the browser security model (e.g. site and origin isolation) and should be avoided if at all possible. For content such as public key fingerprints, I recommend setting a blank
Back to reference 1sandboxdirective even if it means breaking these addons. -
Some addons will have reduced functionality; for instance, Tridactyl can’t create an
<iframe>for its command window. I consider this to be worthwhile since the most important functionality is still available, and because authors shouldn’t feel compelled to support security weakening. I say this as someone who uses Tridactyl often.Moreover, the
Back to reference 2sandboxdirective exposes some bugs in WebKit (i.e. Safari and most GTK-based browsers). On content governed by asandboxdirective without theallow-same originandallow-scriptsdirectives, some WebKit browser features won’t work. One example is media controls. One page on my site has anaudioelement; I addedallow-scriptsto that page so it will work in WebKit-based browsers. WebKit bug 237281 documents the general issue; WebKit bug 225865 and WebKit bug 218086 document specific instances. -
Here’s an overview of PE and my favorite write-up on the subject.
Back to reference 3 -
Each of these flows can be visually displayed using a breadcrumbs list; doing so can meet the WCAG Success Criterion 2.4.8: Location. I opted to meet the criterion a different way. Since all my pages are linked by my site’s global navigation or my “posts” page (also in the global navigation), I just used
Back to reference 4aria-currentand made the currently-relevant entry in my global navigation a<strong>element. However, I later introduced breadcrumbs anyway because I don’t think a simple<strong>element conveys this information clearly enough. -
One example is a utility class for the
Back to reference 5image-renderingproperty. I use it on images that look better withpixelatedrendering. This is a property of the image contents, not the image semantics or placement; a class makes sense. -
Technically, this is only true in idealized circumstances and if you have 0-RTT enabled. If your requests are not idempotent, you probably should stick with 1-RTT. A TCP handshake actually involves one additional round-trip, so you could probably start off with a 30-kilobyte window on HTTP/2 with 0-RTT. HTTP/3 servers with 0-RTT do use a true “zero-round-trip” connection, but they use QUIC instead of TCP. QUIC uses similar sizing logic but I’m not sure about the exact values.
High-Performance Browser Networking by gives a great introduction to how TCP works, if you’d like more details.
Back to reference 6 -
This one-kilobyte limit is a semi-arbitrary rule-of-thumb I came up with. It’s a simple number easier to work with than the number of bytes remaining in the earliest contentful round-trip, yet it typically falls within that quota.
Back to reference 7 -
HPACK and QPACK header compression includes dictionaries containing common header names, and some common header values; HPACK lists them in “Appendix A” of RFC 7541. If these dictionaries contain a given header name or name-value pair, the header name/value’s effective size can be reduced to a single byte. If a header has a value that isn’t covered by the table, consider minifying it by removing unnecessary whitespace.
Remember that if your golden first kilobyte already lists all essential resources, these could be considered premature optimizations. Real bottlenecks lie elsewhere.
Back to reference 8 -
Ironically, that page doesn’t load the main text without JavaScript despite citing a JavaScript requirement as a downside. If you can’t load the page, the same issues with infinte scroll are outlined in the “Accessibility concerns for infinite scroll” section of Infinite Scroll without Layout Shifts by .
Back to reference 9 -
The benefits of containment are especially noticeable when injecting styles into a page. “Dark mode” and “userstyle” extensions perform noticeably better when enough elements receive layout and paint containment. Containment allows browsers to handle changes to an element independently of the rest of the DOM.
Back to reference 10 -
See the “Lighthouse” entry in the “Automated tests” section. Lighthouse benchmarks my machine with a score of around 1320; with that score, it recommends throttling my machine by just under 3.1x to simulate a target mobile device. The Chromium team came up with the throttling formula under idealized conditions (the phone isn’t overheating, battery-saver mode is off, etc); I go further and throttle between 12x and 13x, still shooting for a perfect performance score. This article is the largest page on my site; it often gets a perfect performance score (100) with my stylesheet enabled, but never reaches 100 when I disable CSS containment or remove my stylesheet.
Back to reference 11 -
Version 12.0 of the Tor Browser was a rebase from Firefox 91.x ESR to Firefox 102.x ESR. It was released more than two months after Firefox 91.x ESR reached End Of Life, almost 16 months after Firefox 102.0 was initially released.
Back to reference 12 -
KaiOS is the third most popular mobile OS, after Android and iOS; it’s the second-most popular mobile OS in India. Firefox updates are tied to operating-system updates in KaiOS. Since most manufacturers don’t support KaiOS devices for long (they’re budget feature phones for emerging markets), don’t expect KaiOS users to mass-upgrade their ancient Firefox versions anytime soon. The last KaiOS Firefox update was from version 49 to 84, almost one year after Firefox 84 came out.
Back to reference 13 -
The most recent such removal was the Document Outline algorithm. For years after it was standardized, the Document Outline was ignored by every browser engine. Finally, the WHATWG replaced the Document Outline algorithm with a revised version that involved multiple heading levels. The revised version matches what user-agents and good authors have been doing for decades.
Back to reference 14 -
Can I Use is operated by a single person; check their site footer for donation information.
Back to reference 15 -
There’s actually a surprising amount of overlap between iOS Lockdown mode and the Tor Browser’s security levels. Both disable WebGL, WebRTC, MathML, remote fonts, and JIT compilation. I recommend avoiding reliance features dangerous enough for privacy- and security-conscious users to disable.
Back to reference 16 -
Firefox users can enable “find as you type” by toggling a preference in about:
Back to reference 17config. Chromium (and derivatives) users can install an extension like Type-ahead-find; note that it requires full-page access and performs script injection to work. -
Iterating through a list of font names to see if each one is available on a user’s system is a slow but effective way to determine installed fonts without being granted permission to use the Font Access API. BrowserLeaks has a demo of this approach. Warning: the page might hog your CPU for a while.
Back to reference 18 -
Decoration is more than cosmetic. The color overrides and accessibility sub-section describes how some decorations, like borders, improve accessibility.
Back to reference 19 -
uBlock Origin is a popular browser extension for content filtering; it’s the most popular Firefox add-on. It includes a built-in feature to block all media elements exceeding a user-configurable size threshold.
Back to reference 20 -
WebAIM and the University of Illinois recommend 100 characters; Tangaru recommends an even smaller limit of 80 characters. I sometimes exceed 100 characters for detailed images but usually stay below 80.
Back to reference 21 -
Browser support for displaying alt-text in place of broken images seems good. More information about support for alt-text exposure can be found on Alternative Text for CSS Generated Content. That post seems to indicate that Firefox 81 on macOS 10.15 didn’t display alt-text, but users report correct alt-text display in more recent Firefox versions.
Back to reference 22 -
Once it gains basic support across all browsers and screen readers, I might recommend using
Back to reference 23aria-detailsinstead ofaria-for more complex descriptions. At the time of writing,describedby aria-detailsis only supported by JAWS. WAI-ARIA 1.2 describesaria-detailswith an example similar to the one I gave in code snippet 5. -
Since WHCM sets colors independently of explicitly-defined ARIA roles, it’s a good way to test adherence to the First Rule of ARIA.
Back to reference 24 -
An earlier version of this article recommended a background of
Back to reference 25#111, but two helpful readers sensitive to overstimulation and halation found#191919preferable. -
Lē also shared their experience in A11y Rules, one of my favorite podcasts
Back to reference 26 -
When making an earlier version of this site’s dark-mode color palette, I made the mistake of exclusively testing in cheap or poorly-calibrated displays with bright black points. I mistakenly thought that my
Back to reference 27#0b0b0bbackground was bright enough to prevent halation. Only after testing on a better screen did I realize that it would look almost completely black; I subsequently lightened the background to#111to strike a good balance. -
Practical Typography only renders invisible text without JavaScript. You can use a textual browser, screen reader, copy-paste the page contents elsewhere, use a reader-mode implementation, or “view source” to read it without enabling scripts. All of these options will ironically override the carefully-crafted typography of this website about typography.
I find Practical Typography quite useful for printed works, and incorporated a more moderate version of its advice on soft-hyphens into this page. With a few such exceptions, I generally find it to be poor advice for Web content.
Back to reference 28 -
I can’t confirm if this is also an issue on VoiceOver for macOS, because I haven’t borrowed the hardware required to test it.
Back to reference 29 -
I linked to a snapshot from the Wayback Machine in hopes that the live version of the Smashing Magazine site will get fixed.
Back to reference 30 -
libavif links against libaom, librav1e, and/or libsvtav1 to perform AVIF encoding and decoding. libaom is best for this use-case, particularly since libaom can link against libjxl to use its Butteraugli distortion metric. This lets libaom optimize the perceptual quality of lossy encodes much more accurately.
Back to reference 31 -
I find it quite odd that Microsoft Edge doesn’t support AVIF. Chromium has supported AVIF for a long time, and Edge is based on Chromium. AVIF is a royalty-free format; I don’t know why Microsoft would remove support for it, especially since Microsoft allows adding AVIF support to Windows. I think Edge also removed Chromium’s experimental, off-by-default support for JPEG-XL.
Back to reference 32 -
I say that a skip link is useful to reduce the amount of Tab keystrokes required, but I don’t know a good “threshold number” to signify “too many keystrokes”. If it takes ten keystrokes to reach the main content, it’s probably time to add a skip-link.
Back to reference 33 -
ATs typically let users navigate by headings, landmarks, paragraphs, and links. Most users prefer skipping article content with heading-based navigation. Keyboard users can bind different keys to different modes of navigation, but mobile users can only access one navigation mode at a time.
Mobile users wishing to temporarily switch modes have to stop, change their navigation mode, perform a navigation gesture, and switch back. Mobile users trying to skim an article don’t always find this worth the effort and sometimes stick to heading-based navigation even when a different mode would be optimal.
Back to reference 34 -
At least, it will be until NVDA bug 9343 gets resolved.
Back to reference 35 -
If you’d like to learn more, A guide to designing accessible, WCAG-compliant focus indicators by has far more details on making accessible focus indicators.
Back to reference 36 -
Screen readers aren’t alone here. Several programs strip inline formatting: certain feed readers, search result snippets, and textual browsers invoked with the
Back to reference 37-dumpflag are some examples I use every day. -
I excluded PageSpeed Insights and GTMetrix since those are mostly covered by Lighthouse. I excluded Hardenize and CryptCheck, since their scope is covered by Internet.nl.
I excluded Security Headers, since its approach seems to be recommending headers regardless of whether or not they are necessary. It penalizes forgoing the
Back to reference 38Permissions-header even if the CSP blocks script loading and execution; see Security Headers issue #103. I personally find thePolicy Permissions-header quite problematic, as I noted in August 2021 on webappsec-permissions-policy issue #189. Finally, Security Headers doesn’t have in-depth checks of the values of headers; Internet.nl does a much better job of that. Security should be a thoughtful process, not a checklist.Policy -
My site caches HTML and RSS feed for a few hours. I disagree with webhint’s recommendations against this: cache durations should be based on request rates and how often a resource is updated. I also disagree with some of its
Back to reference 39content-typerecommendations: you don’t need to declare UTF-8 charsets for SVG content-type headers if the SVG is ASCII-only and called from a UTF-8 HTML document. You gain nothing but header bloat by doing so. -
Consider disabling the JIT for your normal browsing too; doing so removes whole classes of vulnerabilities. In Firefox, navigate to about:
config and toggle some flags under javascript..options Code snippet 12: Firefox prefs to turn off JIT compilation javascript.options.ion javascript.options.baselinejit javascript.options.native_regexp javascript.options.asmjs javascript.options.wasmIn Chromium and derivatives, run the browser with
Back to reference 40--js-flags='--jitless'; in the Tor Browser, set the security level to “Safer”. -
LibreOffice can also render HTML but has extremely limited support for CSS. OnlyOffice seems to work best, but doesn’t load images. If your page is CSS-optional, it should look fine in both.
Back to reference 41